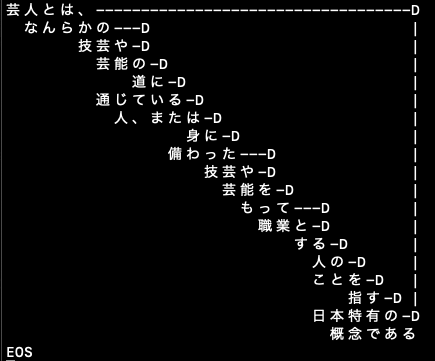
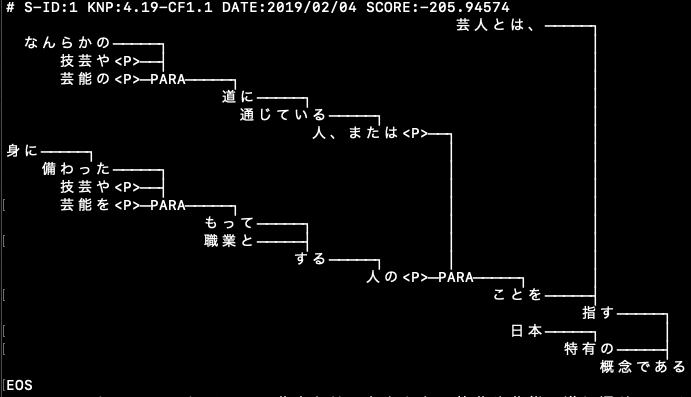
作成したJAVAプログラムJPrologで、夏目漱石「吾輩は猫である」の冒頭部分のパラグラフ全体をprolog化してみた。KNPが一度の処理を300字くらいを限界にしているので、パラグラフ全体を一挙にはできず、文章一つづつのprolog化になり、全体で3.5秒ほどかかった。
まだ、形態素解析の部分や、ノードとリーフの語の形成に不満はあるが、それは後でじっくり治していこうと思う。まず、どれだけやれるのかを確かめたい。この後、さらに長い文書をやらせようと思っている。
swiprologに読み込ませたが、いくつか問題を克服したのち、以下の状態では、正常に読み込んでいる。主に問題は、動詞の活用形と原型のリストをめぐってのものだった。仕様を、いかに記載したように改訂した。
plsample(line0,
node(は,
吾輩,
node(である,
猫,
[ ]
)
)
).
plsample(line1,
node(は,
名前,
node([],
まだ,
node([],
無い,
[ ]
)
)
)
).
plsample(line2,
node(か,
node(で,
どこ,
[生れた, 生れる]
),
node([],
とんと,
node(が,
見当,
node(ぬ,
[つか, つく],
[ ]
)
)
)
)
).
plsample(line3,
node(だけは,
node(いた,
node([],
node(で,
node([],
node([],
node([],
node([],
何でも,
薄暗い
),
じめじめ
),
[した, する]
),
所
),
ニャーニャー
),
[泣いて, 泣く]
),
事
),
node(いる,
[記憶, [して, する]],
[ ]
)
)
).
plsample(line4,
node(は,
吾輩,
node(で,
ここ,
node([],
[始めて, 始める],
node(を,
node([],
node(と,
人間,
いう
),
もの
),
node([],
[見た, 見る],
[ ]
)
)
)
)
)
).
plsample(line5,
node(しかも,
[],
node(と,
node(で,
あと,
聞く
),
node(は,
それ,
node(と,
書生,
node([],
いう,
node(中で,
人間,
node([],
一番,
node(な,
獰悪,
node(であったそうだ,
種族,
[ ]
)
)
)
)
)
)
)
)
)
).
plsample(line6,
node(は,
node(と,
node([],
この,
書生
),
いうの
),
node(を,
node([],
時々,
我々
),
node([],
[捕まえて, 捕まえる],
node([],
[煮て, 煮る],
node(と,
食う,
node([],
いう,
node(である,
話,
[ ]
)
)
)
)
)
)
)
).
plsample(line7,
node(しかし,
[],
node(は,
node([],
その,
当時
),
node([],
node([],
node([],
node(から,
node(も,
node(何という,
[],
考
),
なかった
),
別段
),
恐
),
[し, する]
),
node([],
いとも,
node(なかった,
[思わ, 思う],
[ ]
)
)
)
)
)
).
plsample(line8,
node(の,
node([],
ただ,
彼
),
node(に,
掌,
node(られて,
[載せ, 載せる],
node(と,
スー,
node(られた,
[[持ち, 持つ], [上げ, 上げる]],
node([],
時,
node([],
何だか,
node([],
フワフワ,
node([],
[した, する],
node(が,
感じ,
node(ばかりである,
[あった, ある],
[ ]
)
)
)
)
)
)
)
)
)
)
)
).
plsample(line9,
node(の,
掌,
node(で,
上,
node(の,
node([],
node([],
少し,
[落ちついて, 落ちつく]
),
書生
),
node(を,
顔,
node(が,
[[見た, 見る], の],
node(いわゆる,
[],
node(と,
人間,
node([],
いう,
node(の,
もの,
node(であろう,
見始め,
[ ]
)
)
)
)
)
)
)
)
)
)
).
plsample(line10,
node(が,
node([],
node(だと,
node([],
node([],
node([],
この,
時
),
妙な
),
もの
),
[思った, 思う]
),
感じ
),
node(でも,
今,
node(いる,
[残って, 残る],
[ ]
)
)
)
).
plsample(line11,
node(れ,
node([],
node(を,
第一毛,
[もって, もつ]
),
[装飾, [さ, する]]
),
node(の,
べきはず,
node(が,
顔,
node([],
つる,
node([],
[つるして, つるす],
node([],
まるで,
node(だ,
薬缶,
[ ]
)
)
)
)
)
)
)
).
plsample(line12,
node(が,
node([],
node(にも,
node([],
その後,
猫
),
だいぶ
),
[逢った, 逢う]
),
node(が,
node([],
node(度も,
node(には,
node([],
こんな,
片輪
),
一
),
[出会した, 出会す]
),
事
),
node([],
ない,
[ ]
)
)
)
).
plsample(line13,
node([],
[のみ, のむ],
node(ず,
[なら, なる],
node(の,
顔,
node(が,
真中,
node([],
あまりに,
node(いる,
[突起, [して, する]],
[ ]
)
)
)
)
)
)
).
plsample(line14,
node([],
そうして,
node(の,
node([],
その,
穴
),
node(から,
中,
node(を,
node(と,
node([],
時々,
ぷうぷう
),
煙けむり
),
node([],
吹く,
[ ]
)
)
)
)
)
).
plsample(line15,
node(くて,
node([],
どうも,
咽むせぽ
),
node([],
実に,
node([],
[弱った, 弱る],
[ ]
)
)
)
).
plsample(line16,
node(が,
これ,
node(は,
node(である,
node([],
node(と,
node([],
node(の,
人間,
飲む
),
煙草
),
いう
),
もの
),
事
),
node([],
ようやく,
node([],
この頃,
node([],
[知った, 知る],
[ ]
)
)
)
)
)
).