ニューラルネットのC++プログラムをJAVAに書き換えたら、すさまじく速くなったということは先に書いた。
これでディープラーニングの入り口である、Autoencoder(自動符号化器)のプログラムを作成した。バグもほぼ取れているような感じなので、
https://github.com/toyowa/jautoencoder
に公開している。
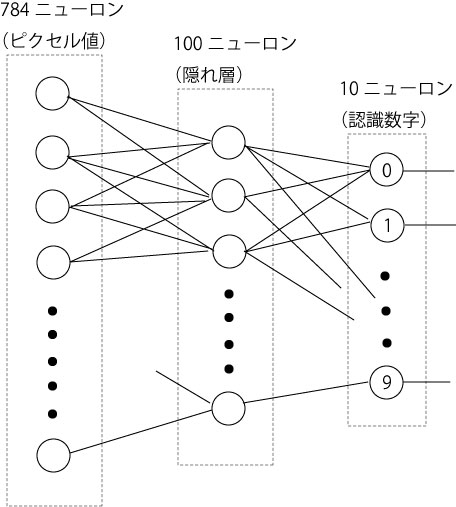
MNISTデータは、入力は、28X28=784ニューロンで、出力は、数字ラベルの10ニューロン。そこで、隠れ層を、300ニューロンと150ニューロン挟んで、4層にした。これまでと同様に、MNISTの6万個の手書き数字データと10000個のテストデータを実行した。
結果は、
<正解数 = 9413 不正解数 = 587 正解率 = 0.9413>
だ。同じプログラムで、改めて実施した、隠れ層400ニューロンだけの、Autoencoder抜きの結果は、
<正解数 = 9310 不正解数 = 690 正解率 = 0.931 >
なので、明らかに、正解率は上昇した。
しかも、隠れ層が300-150で、Autoencoderなしにニューラルネットを実施した場合は、全くダメ、というか収束しないので、Autoencoderの効果は確かめられた。
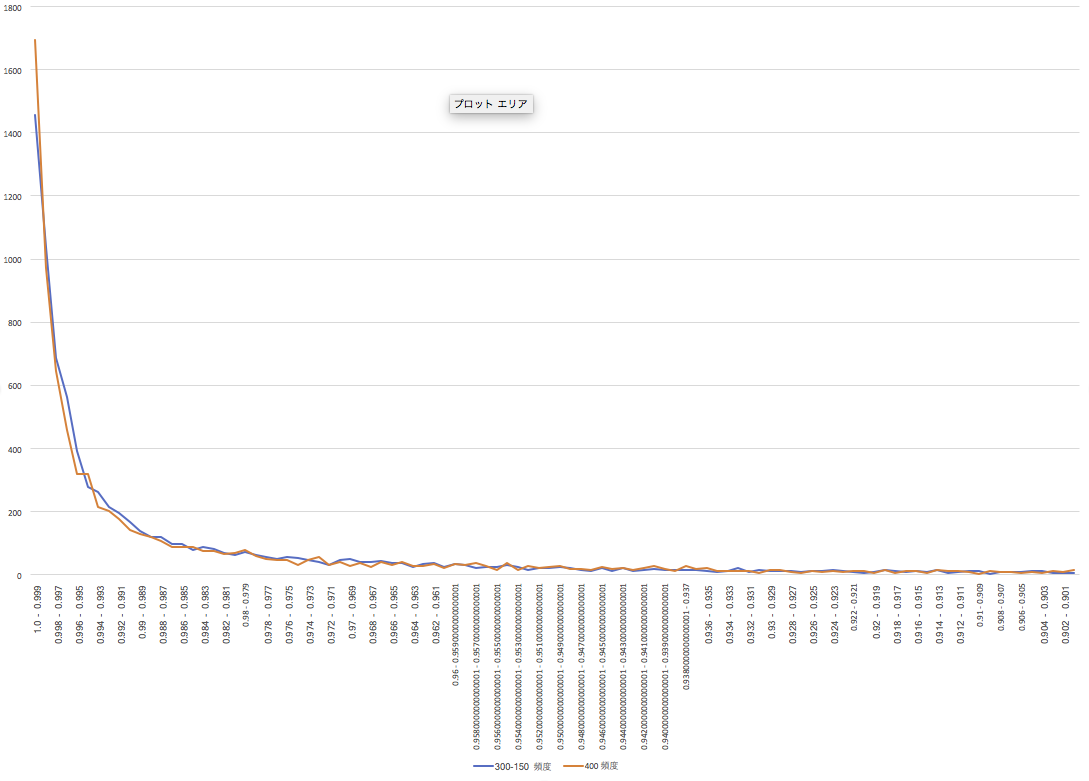
正解率のヒストグラムは、以下のようなものである。400の方が、0.999以上の頻度は多いのだが、総合的パフォーマンスは300-150のAutoencoderの方が高い。理論的に予測されているように、Autoencoderを入れた方が、柔軟に認識ている感じだ。
ニューラルネット、JAVAが速すぎる
半日かけて、ニューラルネットのプログラムをC++から、JAVAに書き換えた。
驚いた。学習のスピードが100倍以上速くなった。私のC++のプログラムが遅すぎるのか。書き方がおかしいのか。いや、そういうレベルの問題ではないくらいに、速くなった。
ニューラルネット、Javaで書き直す
ここまでC++でやっておいてなんだが、プログラム全体をJavaで書き直そうかと思っている。C++のスレッドが、なんだかうまく動かない。ニューラルネットに並列処理は不可欠なのだが、C++ではダメなような気がしてきた。
Javaも十分早くなったし、Javaでニューラルネットのパッケージも作られているくらいだから、RaspberryPIでもjavaは使えるので。そうなると、ロボットのコントローラー全部をjavaにしてしまうかもしれない。
自己符号化器, Autoencoderをニューラルネットに組み込む
スレッド問題は保留にして、ニューラルネットワークが、ほぼ予定通り機能しているような感じだから、ディープラーニングに進む。
画像認識ではなく、ロボットの動作制御に組み込むことを想定すると、いかに数少ないデータで効率の良い判断力をつけるかが問題となる。そういう点では、まず、基本的な自己符号化器を扱えるようにした方が良いと感じた。
自己符号化器は、元々の入力データが持っている特徴を際立たせる事前作業を行うことで、階層が深くなってもその力を活かせるようにしている。プログラミングとしては、ニューラルネット、バックプロパゲーションが組み込まれていれば、拡張は容易だ。
ただ、世間では、あまりこの自己符号化器は使われなくなっているようだが、目的に依存するだろう。
隠れ層のニューロンを400にしたら正解率が落ちた(笑)
MNISTを利用した他の研究を見ていると、私のように隠れ層が100ニューロンというのは例外的に小さい。そこで、隠れ層を400にして60000個の学習データでウェイトを学習させ、同じように10000個のテストをやって見た。
結果、
<正解数 = 9201 不正解数 = 799 正解率 = 0.9201>
で、正解率が1%落ちた(笑)
ただ、正解の時に、どのようなユニット出力になっているかを見ると、さすが隠れ層を増やした結果だなと思わせる。
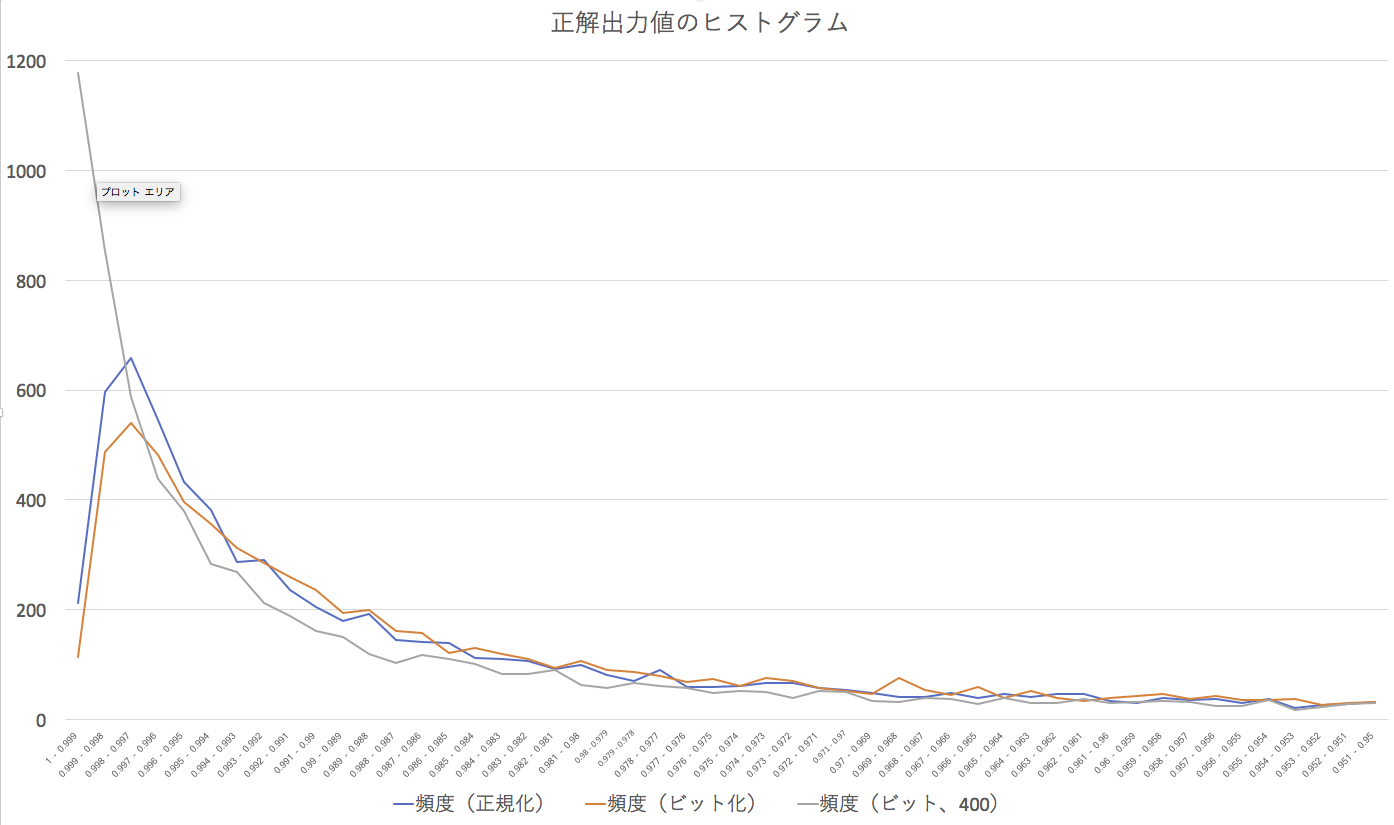
図を見てもらえば明らかなように、先の2つのケースに比べて、その数字のユニット出力が0.999以上、つまり、ほぼ1になっているのだ。認識した数字に対する確信が抜群に高いということだ。「これは間違いなく3だ」とか、ネットワークが言い放っているような感じだ。そのためか、若干汚い手書き文字に対して、厳密な態度を取っている「こんな数字4じゃないだろう!」みたいな上から目線といっても良い。しかし、認識率もそれほど落ちたわけではない。ただ、上昇しなかったのが悔しいだけだ。
学習過程にできるだけ多くのスレッドを使うべき
ニューラルネットワークのプログラムで、元来、並列処理なのにスレッドを一つしか使わずにやること自体が問題だと思う。オプションで使うスレッド数を指定できるようにして、並列処理化を図りたい。
ニューラルネットワークのC++プログラムの公開
作成したニューラルネットワークのC++プログラムを、
https://github.com/toyowa/neuralnet
に公開した。
Gnuのg++用のプログラムで、他では確かめていない。
ネットワーク全体は、Netクラスに、その層(レイヤー)はLayerクラスに、レイヤーの内容であるニューロンは、Neuronクラスになっている。それぞれ、オブジェクト化されて使われる。
細かい説明は、気が向いたらしよう。プログラムを使えるくらいの人は、見ればわかるだろうと思う。
余談だが、私は、このプログラムも含め、C++、JAVA、JAVASCRIPT、Html、PHPなどの開発は、全てNetbeans上でやっている。Netbeansは、最高の開発環境だと思っている。
このニューラルネットワークとバックプロパゲーションは、30年近く前に一度やっていたことなのだ。大きく変わったのは、コンピュータの凄まじい高速化だ。
MNIST手書き数字データで93%の識別率
作成した汎用ニューラルネットワークで、その辺りのパフォーマンスを図る標準データとなっているMNISTの手書き数字データをテストしてみた。
MNISTについては、
http://yann.lecun.com/exdb/mnist/
にデータそのものと解説がある。
手書き数字は、
 こんな感じのもので、数字の一つ一つがデータ化されている。1ピクセルが1バイト(0-255)の値が与えられ、1文字、28X28ピクセルからできている。
こんな感じのもので、数字の一つ一つがデータ化されている。1ピクセルが1バイト(0-255)の値が与えられ、1文字、28X28ピクセルからできている。
データ数は、60000文字の学習用データと10000文字のテスト用データがある。それぞれ、ピクセルデータとそれが幾つの数字を表しているかというラベルデータがある。60000字でニューラルネットを学習させ、ネットワークウェイトを作成し、そのウェイトが、テスト用10000字を正しく認識するかどうかを調べるのである。
ニューラルネットワークは、入力レイヤーが、28X28の784ニューロン、隠れ層(中間レイヤー)は100ニューロン、出力は0から9までの値を出すので、10ニューロンにした。出力は、ネットワークがその画像について判定した値のニューロンだけが発火する(値1になる)ことを見越しているわけである。
78万4千個のウェイトからなる、従って、訓練手法であるバックプロパゲーション(誤差逆伝搬)で、6万個の文字について、毎回これだけのウェイトを微調整しながら最終的に望ましいウェイトを見つけるわけであるから、相当大きめのネットワークである。
データについては、それぞれのピクセルの値を、正ならば1層でないならば0に、ビット化したものと、(0-255)それぞれの値を0から1の間の数に正規化したものと2種類用意した。元のデータのままをネットワークに入れたら、途中で破綻している。正規化したものに全ての情報が入っているので、生データを使う必要はない。
予測的には、正規化して0から1の間の数字にした方が、情報を多く持っているので、良いパフォーマンスを示すのではないかと思われた。0と1にビット化すれば、情報を単純なものにしてしまうのだから。
学習に、3Gヘルツ、8コアの最高スペックのMac Proでも1時間以上かかった。と言ってもこのマックは16スレッド動かせるのだが、プログラムそのものがほとんど1スレッドで動かしているので、相当無駄にしているのだが。逆に、同時にいくつもの学習を同時にさせることはできる。
10000個のテスト用データのテスト結果は、以下のようである。
<正規化(0.0-1.0の間の値)されたデータを用いた場合>
正解数 = 9283 不正解数 = 717 正解率 = 0.9283
<ビット化(0.0か01.0の値)されたデータを用いた場合>
正解数 = 9300 不正解数 = 700 正解率 = 0.93
微妙に正解率がビット化した方がいい。誤差の範囲といってもいいが、何よりも、ビット化して情報を削ったにもかかわらず、正規化したものに匹敵するパフォーマンスを出していることが驚きである。MNISTに掲載されているパフォーマンスと比べるとやや低いが、何の微調整もしていない、ただ作成したものでいきなりテストしただけで、これだけのパフォーマンスを出せれば、私としては合格だ。
正解率は、最大出力を出したユニット番号が、その画像の数字に一致する場合に正解としているのだ、これだけでは、どこまで明確にその数字と判断しているのかがわかりにくい。そこで、正解の出力ユニットがどれくらいの値を出したのかをヒストグラムで示す。基本的にユニットは0から1の間の数字しか出さず、通常、関係ないときはほぼ0に近い値しか出さないことに注意されたい。
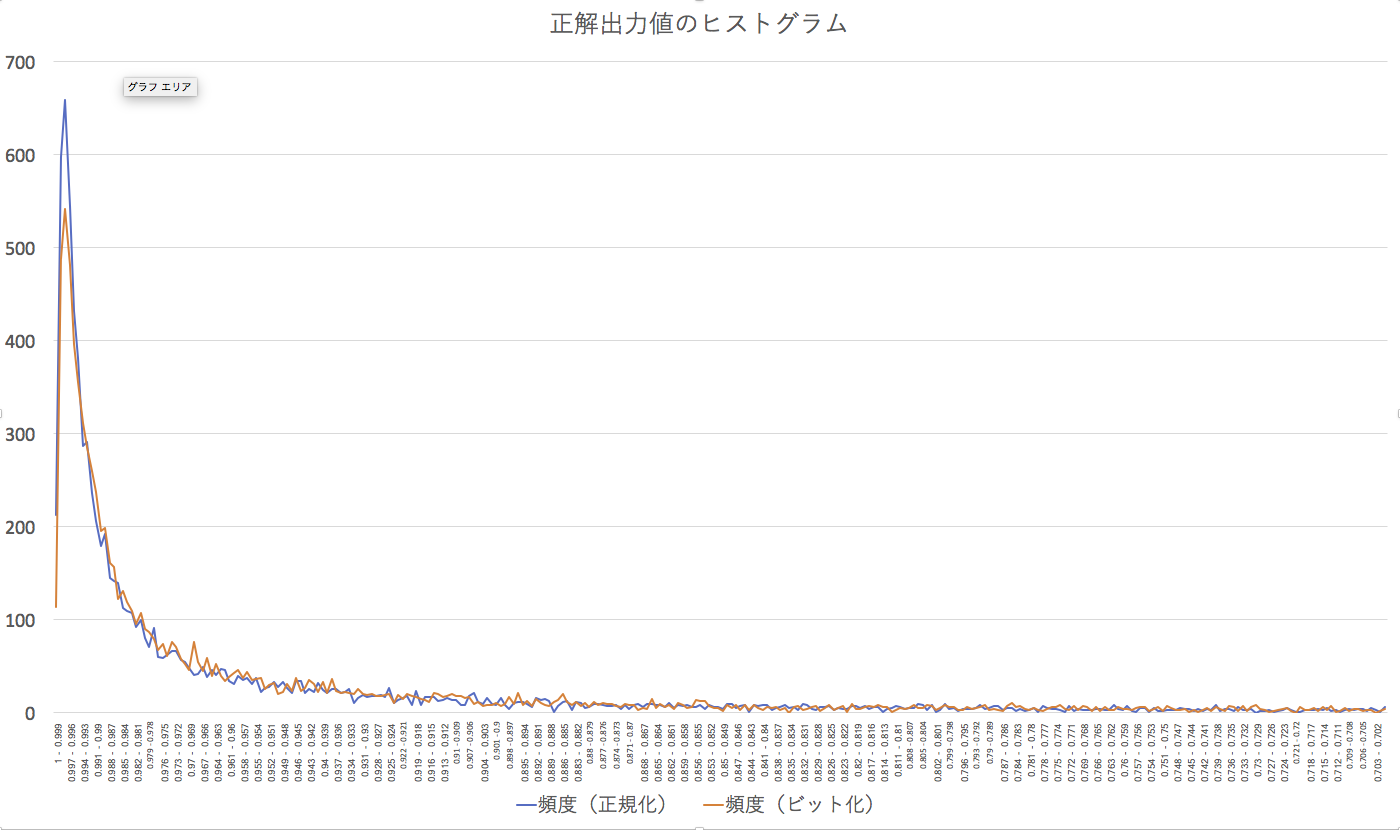 つまり、そのユニットが正解だという場合、ほぼ0.9以上の値を突然、出している(ニューロンが発火している)ということだ。このグラフを見ると、このヒストグラムで示されたパフォーマンスは、正規化されたデータの方が、より1に近い数字で、ヒストグラムがより高く立っているので、パフォーマンスが良いといってもいい。ビット化されたデータをそれよりやや低いところで、パフォーマンスを稼いでいる。
つまり、そのユニットが正解だという場合、ほぼ0.9以上の値を突然、出している(ニューロンが発火している)ということだ。このグラフを見ると、このヒストグラムで示されたパフォーマンスは、正規化されたデータの方が、より1に近い数字で、ヒストグラムがより高く立っているので、パフォーマンスが良いといってもいい。ビット化されたデータをそれよりやや低いところで、パフォーマンスを稼いでいる。
次は、ディープラーニングを組み込む。
ディープラーニング用にニューラルネットの汎用プログラムを書いた(2)
隠れユニットを2層にして、それぞれ2ニューロンあるネットワークで100万回、排他的論理和を学習させた。学習係数は、0.05とごく小さくしてある。1の時は、0.988以上、0の時は、0.02以下とかなりはっきりと識別している。
次は、手書き文字の認識をさせよう。
入力データ 0 1 Layer::printOutput Neuron [ 0 ] => 0.988652 教師出力データ 1 -----------------No.999994------------------ 入力データ 0 1 Layer::printOutput Neuron [ 0 ] => 0.988661 教師出力データ 1 -----------------No.999995------------------ 入力データ 1 1 Layer::printOutput Neuron [ 0 ] => 0.0153844 教師出力データ 0 -----------------No.999996------------------ 入力データ 1 1 Layer::printOutput Neuron [ 0 ] => 0.0153657 教師出力データ 0 -----------------No.999997------------------ 入力データ 0 0 Layer::printOutput Neuron [ 0 ] => 0.00271229 教師出力データ 0 -----------------No.999998------------------ 入力データ 1 0 Layer::printOutput Neuron [ 0 ] => 0.988581 教師出力データ 1 -----------------No.999999------------------ 入力データ 1 1 Layer::printOutput Neuron [ 0 ] => 0.0153556 教師出力データ 0 -----------------No.1000000------------------ 入力データ 1 0 Layer::printOutput Neuron [ 0 ] => 0.988579 教師出力データ 1
ディープラーニング用にニューラルネットの汎用プログラムを書いた
ロボットの姿勢制御にディープラーニングを用いたいと思って、その手始めに、ニューラルネットワーク(誤差逆伝搬:バックプロパゲーション)の汎用プログラムを一昨日くらいから熱を込めて書いた。
汎用性を重視して、レイヤーの数や、その中でのニューロンの数を柔軟に変えられるようにすると同時に、C++らしいオブジェクト型のプログラムにしようとした。ようやくバグがないような感じになって、排他的論理和を識別させてみたが、結構学習に手間かかる。
細かくウェイトを変える(グラディエント値の0.05ずつ調整)ようにして、100万個のデータを学習させて認識させた。中間層は4個で、Neuron[0]というのが、最後の出力層のニューロンの値だ。バイアスニューロンをつけていないからかもしれない。
printOutput Neuron [ 0 ]
が、順伝搬の出力値だ。
-----------------No.999975------------------ 入力データ 1 0 Layer::printOutput Neuron [ 0 ] => 0.986243 教師出力データ 1 -----------------No.999976------------------ 入力データ 0 1 Layer::printOutput Neuron [ 0 ] => 0.986272 教師出力データ 1 -----------------No.999977------------------ 入力データ 0 1 Layer::printOutput Neuron [ 0 ] => 0.986272 教師出力データ 1 -----------------No.999978------------------ 入力データ 1 0 Layer::printOutput Neuron [ 0 ] => 0.986243 教師出力データ 1 -----------------No.999979------------------ 入力データ 0 0 Layer::printOutput Neuron [ 0 ] => 0.0137698 教師出力データ 0 -----------------No.999980------------------ 入力データ 0 0 Layer::printOutput Neuron [ 0 ] => 0.0137697 教師出力データ 0 -----------------No.999981------------------ 入力データ 0 0 Layer::printOutput Neuron [ 0 ] => 0.0137696 教師出力データ 0 -----------------No.999982------------------ 入力データ 1 0 Layer::printOutput Neuron [ 0 ] => 0.986243 教師出力データ 1 -----------------No.999983------------------ 入力データ 1 1 Layer::printOutput Neuron [ 0 ] => 0.0131976 教師出力データ 0 -----------------No.999984------------------ 入力データ 1 0 Layer::printOutput Neuron [ 0 ] => 0.986243 教師出力データ 1 -----------------No.999985------------------ 入力データ 0 1 Layer::printOutput Neuron [ 0 ] => 0.986272 教師出力データ 1 -----------------No.999986------------------ 入力データ 0 1 Layer::printOutput Neuron [ 0 ] => 0.986272 教師出力データ 1 -----------------No.999987------------------ 入力データ 0 1 Layer::printOutput Neuron [ 0 ] => 0.986272 教師出力データ 1 -----------------No.999988------------------ 入力データ 0 0 Layer::printOutput Neuron [ 0 ] => 0.01377 教師出力データ 0 -----------------No.999989------------------ 入力データ 1 0 Layer::printOutput Neuron [ 0 ] => 0.986244 教師出力データ 1 -----------------No.999990------------------ 入力データ 1 1 Layer::printOutput Neuron [ 0 ] => 0.0131984 教師出力データ 0 -----------------No.999991------------------ 入力データ 0 1 Layer::printOutput Neuron [ 0 ] => 0.986272 教師出力データ 1 -----------------No.999992------------------ 入力データ 1 0 Layer::printOutput Neuron [ 0 ] => 0.986244 教師出力データ 1 -----------------No.999993------------------ 入力データ 0 1 Layer::printOutput Neuron [ 0 ] => 0.986273 教師出力データ 1 -----------------No.999994------------------ 入力データ 0 1 Layer::printOutput Neuron [ 0 ] => 0.986273 教師出力データ 1 -----------------No.999995------------------ 入力データ 1 1 Layer::printOutput Neuron [ 0 ] => 0.013199 教師出力データ 0 -----------------No.999996------------------ 入力データ 1 1 Layer::printOutput Neuron [ 0 ] => 0.0131987 教師出力データ 0 -----------------No.999997------------------ 入力データ 0 0 Layer::printOutput Neuron [ 0 ] => 0.01377 教師出力データ 0 -----------------No.999998------------------ 入力データ 1 0 Layer::printOutput Neuron [ 0 ] => 0.986244 教師出力データ 1 -----------------No.999999------------------ 入力データ 1 1 Layer::printOutput Neuron [ 0 ] => 0.0131984 教師出力データ 0 -----------------No.1000000------------------ 入力データ 1 0 Layer::printOutput Neuron [ 0 ] => 0.986244 教師出力データ 1 -