ロボットの足の裏に片足四個ずつつけようと思っている圧力センサーFSR402をテスターでテストしてみた。確かに抵抗値は変化する。
ディープラーニングプログラム(AICORO)、RaspberryPiでマルチスレッド並列処理化
先に、Javaで書いたAutoencoderのディープラーニングプログラム(以下AICORO)をマルチスレッド化して並列処理にしたら、あまり効果がなかったと書いた。それは、CpuがCore i7の3GhのMacでの話だった。「ああ、失敗したな〜」という感じで、終わった。
今日から、またロボットの方で、センサーをテストしようとRaspberyPi3を動かして、ついでだからAICOROを動かしてみた。(JAVAもNerbeansも入れてある)スレッド一個で処理するものを動かしたのだが、なんとなく遅い。784,600,400,300,10という隠れそう3つのネットワークをホワード処理だけで動かしたのだが、1サイクル25ミリ秒くらいかかる。ちょっと遅いなと思った。MACだと時間を測れないほどバリバリに速いのだが。
もしかしてと思って、昨日作ったマルチスレッドのAICOROを動かしてみた。10スレッドの並列処理をするバージョンだ。「あれ!!」1サイクル10ミリ秒くらいで処理する。「いいじゃない!!」
RaspberryPi3は、CPUが4コア持っているので、8スレッドあたりは十分使えそうなきがする。10スレッドはちょっと多いかもしれないが。
初めて、マルチスレッド、並列処理が役に立つことがわかって嬉しい!!
ロボット制御のイメージ
現在考えているAIを軸としたロボット制御のイメージを少し書いておこう。
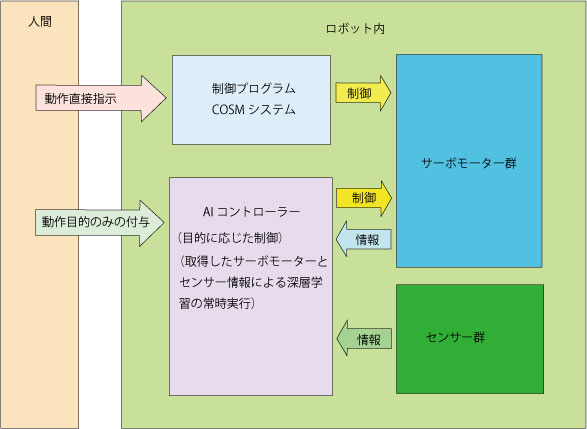 基本、歩く立つなどの目的を与えると、AIコントローラー自身がサーボモータを制御するようにシステムを作る。AIコントローラーは、サーボモーター角度群、センサー情報とその変化を取得して、自ら学習する。それらの情報は、人がCOSMを通してロボットを動かしている状況の中で取得する。
基本、歩く立つなどの目的を与えると、AIコントローラー自身がサーボモータを制御するようにシステムを作る。AIコントローラーは、サーボモーター角度群、センサー情報とその変化を取得して、自ら学習する。それらの情報は、人がCOSMを通してロボットを動かしている状況の中で取得する。
AIコントローラーは、モーターとセンサーの与えられた状況の中で、次のステップでサーボモータのどのような動きのパターンに持っていくのかをニューラルネットワークから出力して、それに基づいてサーボモーターが動く。
AIコントローラーのネットワークは、事前学習とともに、取得する情報に基づいて常時学習する。
学習には、動きの成功と失敗のイメージも学習に組み込む。
圧力センサーとADコンバーター
ロボットの足の裏に、片足四個ずつ、合計八個の圧力センサーをつけて、ロボットの実際の重心の状況をロボット自身が捉えられるようにしようと、センサーとADコンバーター中継する部品を製作し、コンバーターをRaspberryPiの基板上に置いた。データをSPIで撮ろうと思っているが、うまくいくだろうか。
加速度センサーも追加で四個つけるので、センサーだらけになるが、それらのセンサーは、人間側のプログラムが情報を処理するのではなく、ロボットのAIで処理するように思っている。だからこんなにセンサーをあちらこちらにつけるのだが。


マルチスレッド化
オートエンコーダーなどのディープラーニングをマルチスレッド化してみたが、少しも速くならなかった。レイヤーにあるニューロンの出力計算やDeltaの計算をスレッドに分散させてみたのだが、それだけでは速くならないどころか、微妙に遅くなっている(笑)
スレッド化のオーバーヘッドが、そのメリットを上回っているのだと思われる。マルチスレッドの入れ方も悪いかもしれない。今の状態で十分速いと理解すべきだろう。当面、手を出さない。
ディープラーニング(Autoencoder)の事前学習段階における「過学習」問題:ネットワークの個性が表れたという問題
オートエンコーダーなどのディープラーニングは、元のニューラルネットワークが、勾配喪失や過学習の問題で行き詰ってしまったのを打ち破ったものだった。実際、私も、その有効性を確認できた。ただ、ひとつひとつの隠れ層の事前学習を過剰にやると、問題も起こってくることもわかった。
例えば、先の記事にも書いたが、入力層と出力層以外に、隠れ層の数を3層にして、それぞれのニューロン数を600、400、300にして、隠れ層の事前学習も、60000個の文字を一通りやるだけにする。すると、事前学習は収束しないのだが、Autoencoderののちに実施したテストでは、96%の正解率に上昇した。しかし、これで、各隠れ層の事前学習を収束するまで徹底的にやるとどうなるか。ここでは、ひとつの層を通常6万回のところを、それをさらに六回繰り返して、36万回データを使って事前学習させたら、正解率が88.7%まで落ちてしまったのだ。
これだと、ああ、事前学習も過学習に陥るのだな、ということになる。
しかし、実はそう単純なことではないのだ。そのことを見るために次の図を示す。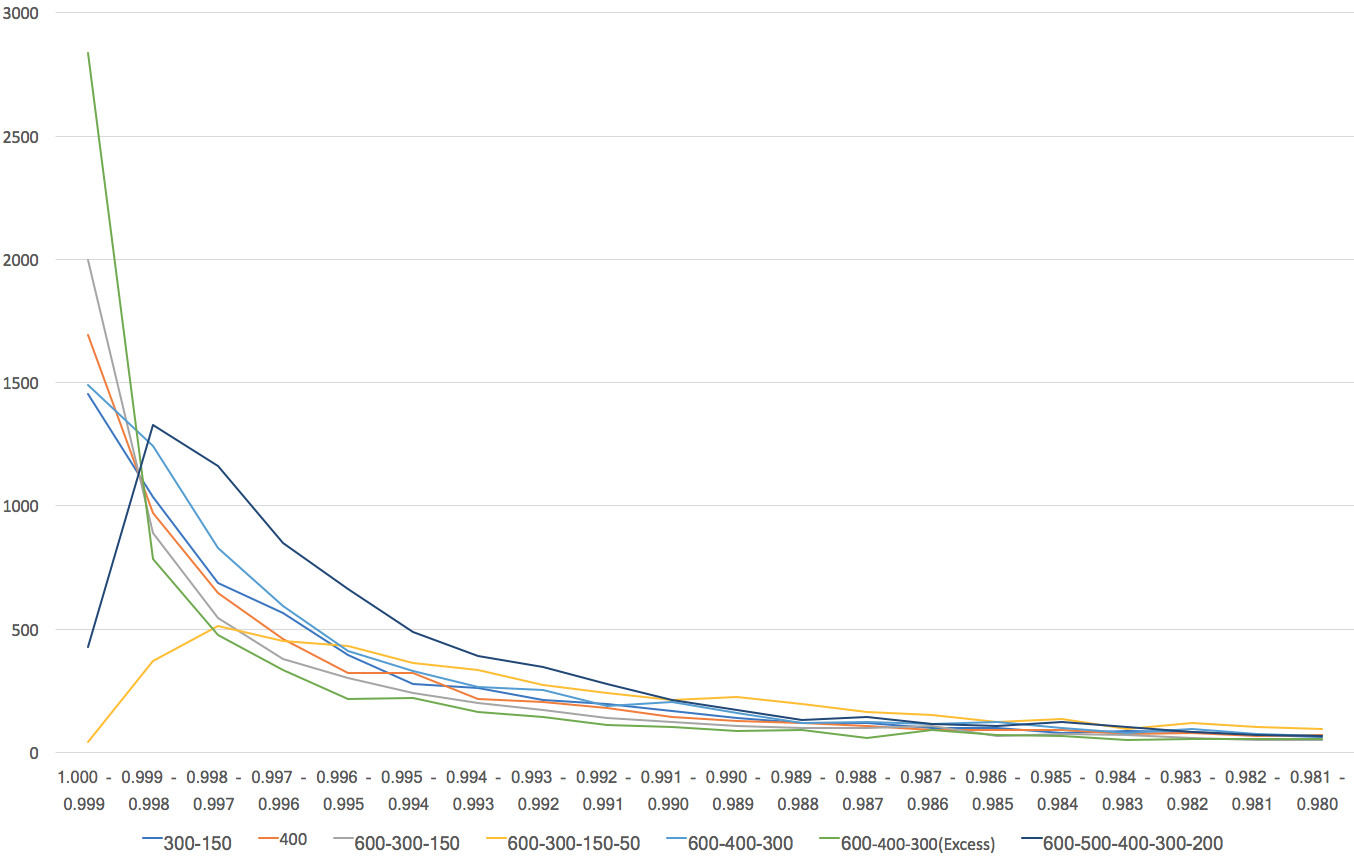
この図で、緑色の線が、Autoencoderで過度に学習させた先のネットワークだ。驚くべきことに、正解した出力ユニットの出力値が3000近くが0.999以上(最大値は1.0)で出力しているのだ。
つまり、自分が正しいと判定したことに強い確信を持っているということだ。あるいは、せいか率を犠牲にしても、そういう確信を持ちたがるネットワークだと言って良い。これに対して、過度に学習させなかったものは、正解率は高いが、だいたいそうだろう、という感じで答えを出してきていることがわかる。
結局、ネットワークに個性が出てきたのだ。正解ということに確信を持ちたいというネットワークと、いやいや、だいたいそうだろうと答えるタイプのネットワークが現れたことになる。
問題は、応用の場合、ロボットの小脳としてどちらのタイプのネットワークを使うべきかということだ。
MNISTの識字率、96%になったが
ディープラーニングの自己符号化手法で、入力層はピクセル数の784、隠れ層を順に、600、400,300、出力層は数字の0から9に対応させて10ユニットというネットワークの学習とテストをしたら識字率は、96%になった。これまでのをまとめると
| モデル | 隠れ層 | 確信度(正解ユニットの出力が0.8以上のデータ数) | 正解率(%) | 学習法 |
| A | 400 | 8435 | 93.1 | 通常 |
| B | 300-150 | 8557 | 94.13 | 自己符号化 |
| C | 600-300-150 | 7848 | 89.37 | 自己符号化 |
| D | 600-300-150-50 | 7893 | 90.06 | 自己符号化 |
| E | 600-400-300 | 8953 | 96.04 | 自己符号化 |
この確信度について説明しておこう。認識した数字は、最終層の10ニューロンのどれが発火しているかで判断するが、成果率は、単に一番出力値の大きなニューロンを選んでいる。例えば、他の九個のニューロンが0.1以下の値で、8番目のニューロンが0.15でも、これは8と認識したとしてそれが正解ならば正解としているのである。
そうではなくて、その出力ニューロンの発火を0.8以上の値を出していない限り発火と認めないとした場合の正解数を確信度としている。
すると、この確信度でもモデルEのパフォーマンスが最も高い。つまり正解率でも96%と最も高いが、0.8以上の発火に限定しても、ほぼ90%の正解率になる。
ただ、一月になるのは、このモデルE以外の自己符号化は、各層の自己符号化の学習で、36万回の学習をやらせて、やや過学習になったのかもしれないと思っている。モデルEは、データ数の60000回で、各層の事前学習もやめている。
その辺りのこともこれから確認したい。
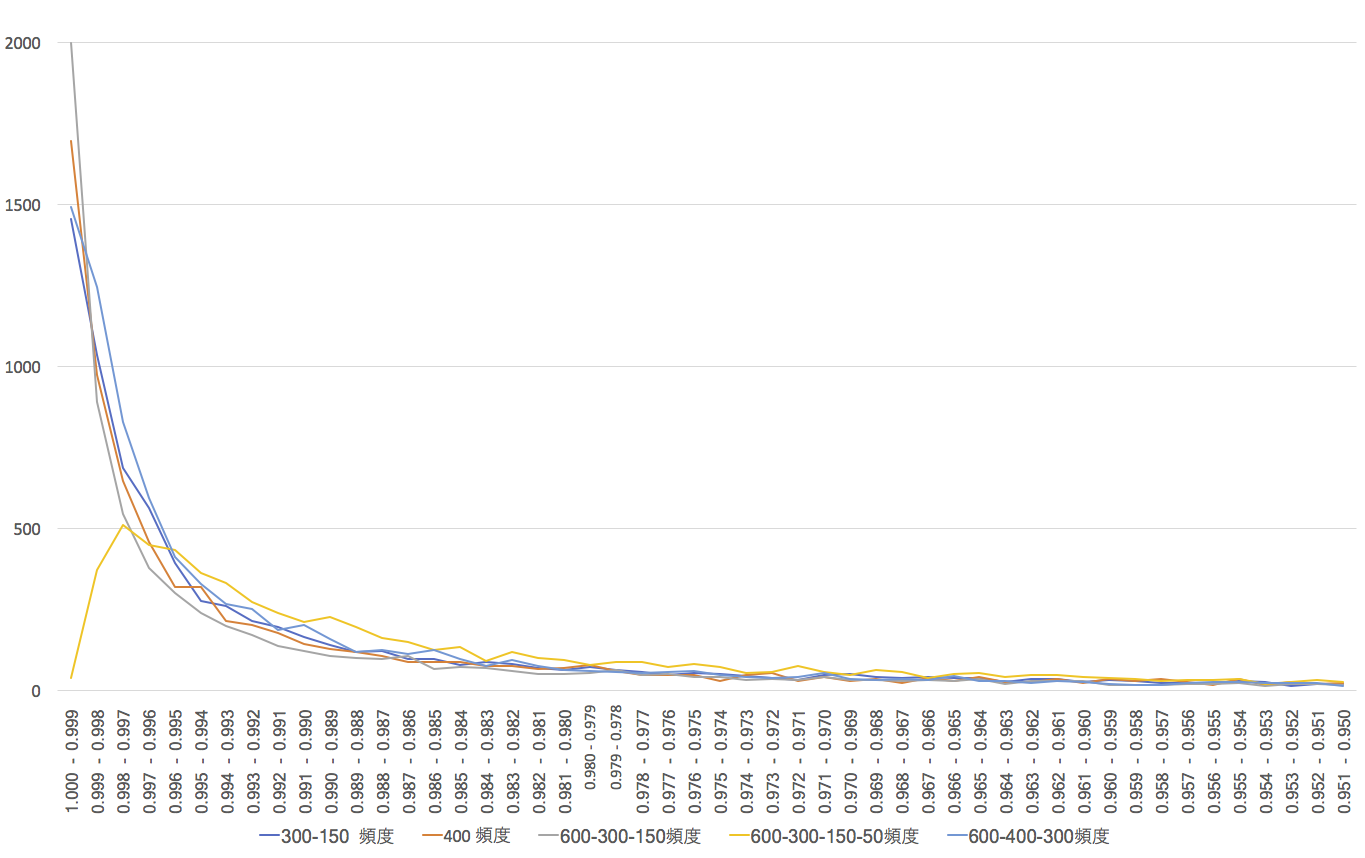
正解ニューロンの発火出力ごとのヒストグラムは以下のようになっている。発火値が0.95以上のものをあげているが、ほとんどの正解が高い発火度で実現しているのは確認できるだろう。
JDeeplearningのプログラム概要(2)
プログラム本体こちら https://github.com/toyowa/jautoencoder
ここでは、JDeeplearningの個々のクラスの説明をしておく。クラス内の主なメソッド(メンバー関数)の説明をする。
<JDeepLearningクラス>
メインクラスだ。mainのスタティック関数が入っている。
public static void main(String[] argv)
冒頭で、自分、JDeepLearningクラスのインスタンスdplを作成する。
何よりも、プログラムを開始する関数がだ、ひたすらオプションの処理をしている。オプション処理後に、
dpl.dataProc.setTrainData(dpl.dataFileName);
で、データを読み込んでいる。
そして、オートエンコーダーなら
dpl.execAutoencoder(topology);
普通のニューラルネットならば、
dpl.execNeuralnet(topology);
という、自分のクラスのメソドを呼び出している。
void execAutoencoder(int[] topology)
オートエンコーダーの実行関数である。(1)で説明したように、隠れ層ごとのサブネットワークを形成する。形成してから、
execNeuralnet(topology)
を呼び出して、バックプロパゲーションでウェイトを作成し、隠れ層ごとにこれを繰り返して、最後は最終層へのウェイトをランダムに作成した、これまでのウェイトと合同させて、ファインチューニングのオリジナルなネットワークを形成して、
execNeuralnet(topology);
に渡している。
ここで、
static double[][][] reserved_weights;
というウェイトを保持するスタティックな3次元配列reserved_weightsが重要な役割を果たしている。第1次元は、レイヤー番号で、0番が第1レイヤーであることに注意してほしい。0番レイヤーには入力ウェイトがないから無駄にならないようにそうしている。第2次元は、そのレイヤーのニューロン番号を指定し、第3次元は、その中のウェイト番号である。配列をメモリー状にインスタンス化する時、ウェイト数は、ニューロンごと(レイーヤー数に基づいて)に異なっているのだが、各レイヤーのニューロン数の最大数で作ることにしている。そして、この配列にデータがあると、Neuronクラスがインスタンス化されるときに、ウェイトの初期値をランダムな数ではなく、ここにある値で初期化されるように作られている。
だから、実行オプションの-weightsでウェイト配列が指定されると、そのウェイトがこのスタティックな、reserved_weightsに保持され、自動的にNeuronクラスのインスタンス化の時にセットされるのだ。
void execNeuralnet(int[] topology)
ニューラルネットワークを起動する。基本、順方向に出力を作る作業と逆方向に、バックプロパゲーションを実行するという、二つの作業をやっている。テストの時は、順方向の作業しかしない。
冒頭で、関数引数のtopologyに基づいて、ニューラルネットワークを作り上げる。具体的には、のちに説明するNetクラスを作り、その中に、Layerクラスで、レイヤーを作り、さらにその中で、Neuronクラスでニューロンを作成するという入れ子構造でネットワークを作成している。つまり、Netのインスタンスの中にレイヤーの数だけLayerインスタンスを作り、各レイヤーの中に必要なニューロン数のNeuronインスタンスを作るわけである。そのかくNeuronインスタンスがウェイトを保持している。
オートエンコーダーで呼び出される場合は、出力の教師学習データが、入力データと同じなので、その辺りの場合分けがされている。
<Netクラス>
Netクラスは、ネットワークの構造と、内部機能を実現するメソッドを保持している。
メンバー変数は、
double [] outputs;
Layer [] layers;
int [] topology;
double adjusting;
で、最初が、出力値を保存している変数、次が、ネットワーク内のレイヤーを保持している変数、topologyは、Netクラスがインスタンス化される過程で与えられるネットワーク構造を保持している、最後のadjustingがバックプロパゲーションでウェイトを調整する係数なのだが、ほとんど、0.15のままにしていて、変更の気持ちがなかったので、このクラスのコンストラクタ内で値を与えて終わりにしていたが、これも実行時オプションで指定できるようにすべきだ。次の改訂ではそうしようと思う。
String makeAutoencoderData(Data dataProc)
オートエンコーダーで次の隠れ層のウェイト形成のための入力データを作成する。つまり、前の隠れ層の時の第1層のウェイトを使ってその前の入力データから出力データを作成するわけである。
tmpout_時間.txt
というファイル名にして保存している。
String printAllWeights(int iteration, String dataFileName)
ネットワークの全ウェイトを出力する。ファイル名は、
weight_時間.wgt
である。ここのレイヤーの出力、ニューロンの出力はそれぞれのクラスに下請けに出す。
void adjustingPreLayerWeightsOut(int layerNo)
ニューロンは、そのニューロンへの入力側のニューロンからの結合ウェイトと、出力側へのウェイトの両方を保持することになっている。なぜそうしているのかといえば、順方向への出力値の計算は、入力側のウェイトデータが必要で、誤差逆伝搬の計算においては、出力側のウェイトが必要だからである。ニューロンに関わる計算はニューロンクラスのメソッドで行われる。ただ、この入力側ウェイトと出力側ウェイトは、あるニューロンの出力ウェイトは次のレイヤーのニューロンの入力ウェイトになるので、両者は同じものでなければならない。それは、ここのニューロン内の計算でもダメで、レイヤーもまたがるので、このNetクラス内のメソドで整合性を取るようにしているのだ。
これを書いている時に改めても直したら、余計な場所で使われているの気づいて直した(このメモのおかげでバグフィックスできた!)。実質計算に影響はないが、微妙に速さが変わったかもしれない。試してみたが、計算結果には影響なく、速さの変化はわからない。
ただ、一つ大事なことを書いておくと、この、Deltaに基づくウェイトの訂正は、ネットワークの全てのDeltaを計算し終えてからにしなければならない。従ってその後に、ウェイトの整合性は図られる。
void getForwardOutput(double [] initVal)
ウェイトに基づく、順方向の出力値の計算をネットワーク全体で実施する。レイヤー、ニューロンに実際の計算は下請けさせている。
void execBackpropagation(double [] deltaE)
誤差逆伝搬の計算。実際の計算は、下請けに任せている。
<Layerクラス>
メンバー変数は以下の通りである。
Neuron[] neurons;
double[] layerOutput;
double[] layerDelta;
double adjusting;
int layerNo;
レイヤークラスは、ネットワーククラスとニューロンクラスの間を取り持っている感じで、大事な計算はあまりない。省略。
<Neuronクラス>
ニューロンクラスのメンバー変数は、
int neuronNo;
int layerNo;
double adjusting;
boolean inputNeuron = false;
boolean outputNeuron = false;
double [] weightsIn;
double [] weightsOut;
double [] prev_output;
double output;
double delta;
double value;
である。
コンストラクタで、ウェイトを組み込むのが大事な作業だ。JDeepLearningのクラスのところでで書いたが
JDeepLearning.reserved_weightsが入っていれば、それをウェイトに組み込み、なければ乱数で作成する。
乱数で作成する時に、単に0から1までの間の数字にすると、出力値が大きくなりすぎてダメになるので、その乱数を入力側のウェイト数で割って正規化する。これで、改善された。
weightsIn[i] = Math.random() / (double) inputNum;
となっている。
void getNeuronDelta(double[] prev_delta)
バックプロパゲーションでいうDelta値をこのニューロンについて計算する。入力値の合計valueで、シグモイド関数の微分値の値を計算する必要があるのだが、
delta = 0.0;
for (int i = 0; i < prev_delta.length; i++) {
//前の層のデルタに、そのニューロンとのウェイトをかけたもの
delta += prev_delta[i] * weightsOut[i];
}
double ev = Math.exp(-value);
delta = delta * (ev / ((1 + ev) * (1 + ev)));
で、計算している。
void getNeuronOutput(double [] prev_output)
順方向の計算を行う関数だ。
<Dataクラス>
ファイルの入出力を担う関数だが、特別なことはないので省略する。データがどのように保存され読み込まれるのかが見れば分かるはずである。
JDeeplearningのプログラム概要(1)
https://github.com/toyowa/jautoencoder
で公開しているプログラムの覚書を書いておこうと思う。これから、ロボットのセンサーを増やす作業に入るので、どういうプログラムだったか忘れてしまいそうなので。この(1)では、全体的なことを書いておく。
1。データに関して
データのフォーマットは、
https://github.com/huangzehao/SimpleNeuralNetwork
のサイトのプログラムを参考にさせてもらった。(プログラムは、独立に私が自分で書いたものだ。プログラムは参考にするほど理解できなかったが、自分で書かないと使えないだろうと思ったから)
データの最初の1行は、
topology: 784 400 10
のようにネットワーク構造を書く。ここで、784が入力レイヤーのニューロン数。以下出力ユニットまで、にゅう論数を書いていく。レイヤーの数にもニューロン数にも制限はない。
その後に続いて、in:とout:の接頭語に続いて、交互に、入力データと出力データを空白を区切って書いていく。
MNISTの手書き数字データに関しては、データの読み取りは、
http://nonbiri-tereka.hatenablog.com/entry/2014/09/18/100439
を参考にさせていただいて、それを上記のデータフォーマットに書き直したものだ。
https://github.com/toyowa/jautoencoder/tree/master/MNIST
に変換用のプログラムをおいてある。
データプログラムは、実行時オプション -dataで指定できる。
2。ウェイトファイル
学習後にウェイトデータを吐き出し、テストの時はそのファイルを実行時オプション -weights で指定して読み込むことになる。ただし、ウェイトファイル名は、wgtのさフィックスがないと拒否するようにしている。データと間違わないように。データのさフィックスは特にチェックせずに読み込む。
吐き出されたウェイトファイル名には、そのファイルが作成された日時が秒までつくので、識別できると思う。ウェイトファイルの頭の部分に、その学習のネットワーク構造やパラメータや、繰り返し数などが書かれている。
-------------------
File name: [ weight_170603192205.wgt ]
Iteration: 179997
InputData: trainingData.txt
Topology: 784 300 150 10
Adjusting: 0.15
Label: Pre_neuron No. -> Layer No. : Neuron No. = Weight
Weight: 0 -> 1 : 0 = 0.0003876341
Weight: 1 -> 1 : 0 = 0.0011203298
Weight: 2 -> 1 : 0 = 0.0004425993
Weight: 3 -> 1 : 0 = 0.0007930749
...........
...........
---------------------------------
なお、テストじゃない時にウェイトファイルを指定すると、そのウェイトを読み込んで、そこに書かれているそれまでの学習の実行の続きをやることになる。何回かに分けてやりたいとか、中間状態を見たい時には、そのような方法もできる。プログラムのデバッグの時は、一回だけ学習させるということもやった。実行時ぷションの、-maxiterで1を指定すると一回だけやる。
なお、-maxiterを指定しないと、データがある限り学習を続ける。
3。テスト
テストの時は、できたウェイトファイルとテスト用データの両方を実行時オプションで指定して、-test オプションを付け加えれば良い。当たり前だが、ウェイトファイルとテスト用データは、ネットワーク構造に関して整合的でなければならない。-weightsでウェイトを指定しないと、当然だが、ランダムに与えたウェイトでテストしてしまうので、テストは無意味だ。チェックして排除するようにすべきだったかもしれない。テスト結果はコンソールに出力される。
4。オートエンコーダー(Autoencoder):深層学習
実行時オプションで -auto をつけると、オートエンコーダーとバックプロパゲーションで学習する。オートエンコーダーとは、隠れ層へのウェイトを1層ずつ、一つの圧縮符号化器のように作っていくことだ。例えば、MNISTで、入力784ニューロン、300と150の隠れ層、出力層が10ニューロンだとしよう。それぞれのレイヤー(層)にA,B,C,Dという名前をつけよう。
まず、ABにA'というAと同じニューロン数のレイヤーをつけて、A'の学習データとして、Aと同じものを使うという作業をする。そして、ウェイトをバックプロパゲーションで形成するという作業をする。一見無意味なようだが、よく考えてみると重要な意味を持っている。AがA'で再現されるんだが、BはAよりもニューロン数が少ない。それが再現されるということは、Bの出力は、Aから入力されるデータの特色をすでになんらかの形で組み込んでいるということである。つまり、ニュー力データだけで、すでに学習してしまっているのである。これでAからBへのウェイトをまず作る。次にそこで最終的に得た出力を利用して、BCB'というネットワークを作成し、その先のネットワーク出力で、自己学習させるのである。Bの入力と、学習用のB'のデータはまた同じである。もちろんニューロン数も同じである。そうすると、BC間のウェイトがまたCで特徴が凝縮されるように形成される。最終的にこのようにできたAB間のウェイトBC間のウェイトを使って、元のABCDのネットワークを元々の学習用出力で学習させる。この時,CD間のウェイトは、私の場合、ランダムに作成したものにしているが、正解かどうかの確信はない。でも多分正しいだろう。これが、オートエンコーダーである。
少なくとも、MNISTのデータについては、うまく機能している。
-autoを指定すると、元のネットワークトポロジーが、5層でもそれ以上でも、同じようにやってくれる。試してないが、はずである。
C++とJAVA
本当に、JAVAの速さに驚いた動揺は未だに冷めない。784X300X150X10のネットワークをサクサクと学習する。ウェイトが、784X300+300X150+150*10=281700個ある。この順方向の計算と誤差逆伝搬によるウェイトの修正を一つのデータに関して行うのにかかる時間は1.67ミリ秒なのである。つまり、60000個のデータを約100秒で修正し終えるので、1サイクル28万個のウェイトを使った一個のデータの計算と修正には、0.00167秒、つまり、1.67ミリ秒しかかからないのである。
本来、JAVAに乗り換えたのは、スレッドの並列計算を導入しやすくする目的だったが、今の所、必要ないので1スレッドで動かしている。いずれ、使用スレッドを指定できるようにするつもりだ。
それはそうと、書いておきたかったのは、JAVAにして改めて、C++の違いに「えっ!」と気づいたことがあったからだ。C++とJAVAは、とてもよく似ていて、書き換えはスムーズにできる。今回、やってみて、クラスを配列に入れた時の振る舞いが違う。
例えば、仮にNeuronというクラスを作成して、この複数のインスタンス(オブジェクトというべきか)を配列neuronsに入れるとしよう。
C++の場合は、vectorを使って、インスタンス neuronを
vector<Neuron> neurons;
neuron.push_back(neuron);
としてvector配列に入れる。
この配列から、
Neuron neuron = neurons.at(1);
という感じで取り出して、このneuronの何かのメンバー変数の値を変更したら、
neuron.at(1) = neuron;
として戻してやらなければ、配列の中に保持されているインスタンスのメンバー変数の値は変わらない。
しかし、JAVAはクラス配列のインスタンスを取り出して、その値を変更すると、元の配列の中のインスタンスそのものの値も変更されているのだ。
だから、埋め戻しが不要だ。
C++愛好家とJAVA愛好家との間では、参照渡しなのか値渡しなのかがよく議論になるが、それと同じようなことだ。もちろん、JAVAのような仕様の方が助かる。なんだから、時間ロスも少ないような気がする。