文章をロジカルに二分木として作成する課題の初めに、膨大な二分木を複数語で検索するというの自在にできるようにしたい。
複数のキーワードをリストで与えて、二分木の中からそれらを同時に持つものを抽出する。
例えば、次のような文章を考える(実際 wikipediaの一文)。
「これに基づいたゲンギスと呼ばれる六本足のロボットは、いわゆる脳を持たないにも関わらず、まるで生きているかのように行動する。」
これをすでに何度か述べた方法(javaで書いたプログラム)でprologの二分技化すると次のようになる。
node(の,
node([],
node(と,
node([],
node(に,
これ,
[基づいた, 基づく]
),
ゲンギス
),
[[呼ば, 呼ぶ], れる]
),
[[[六, 数量], 本], [足, '動物-部位']]
),
node(は,
[ロボット, '人工物-その他'],
node(を,
node(いわゆる,
[],
[脳, '動物-部位']
),
node(にも,
[[持た, 持つ], ない],
node(かの,
node([],
node(ず,
[関わら, 関わる],
まるで
),
[[生きて, 生きる], いる]
),
node(に,
よう,
node([],
[[行動|...], する],
[]
)
)
)
)
)
)
).
これでは、二分技とは見えにくいと思うので、図で書くと次のようになる。
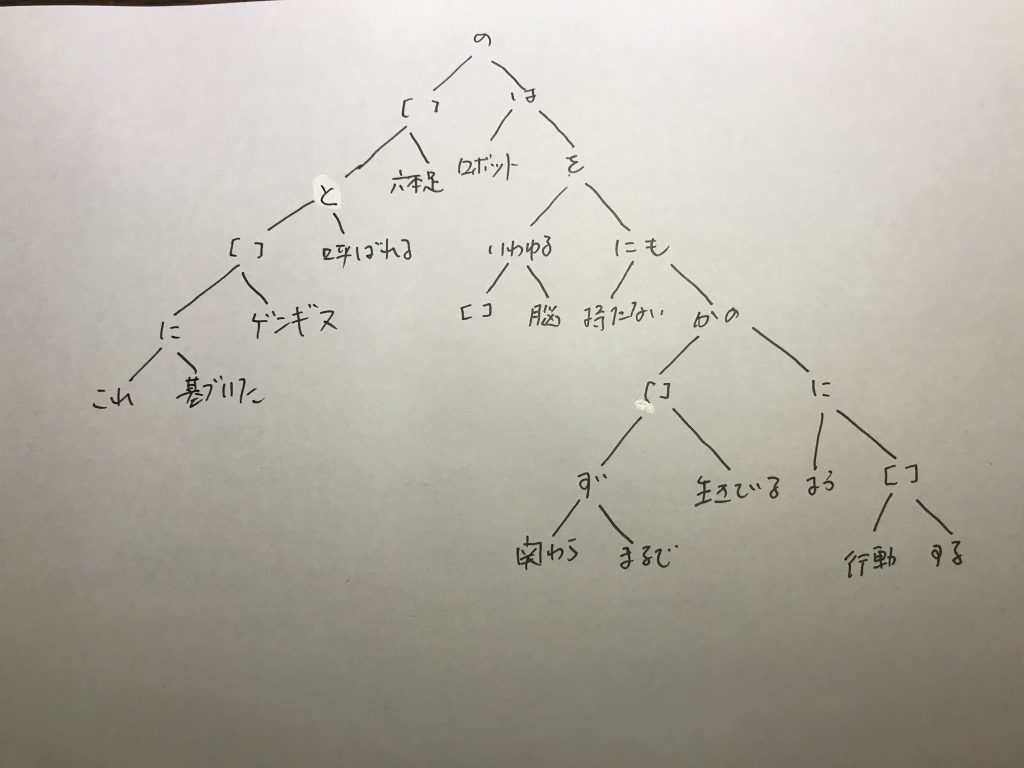
[ ]は、空リストだ。基本、ノードに体言(名詞、動詞)はこない。「の」は、強い助詞なので、全体のルートに来ている(この辺りの手続きは別の記事で書いている)。左側には個別的、特殊な事柄が、右側には、一般的な事柄が吐き出されている。しかし、こうした二分木の構造は全体としてみれば、二次的なものだ。
全体として、端末の左の葉の言葉が少ないという特徴も出ている。
検索用に、次のようなprologのプログラムを作成した。左からの検索プログラムしかまだ書いていない。
%%
%% キーワードのリストから部分二分木を拾ってくる
%% 2019年4月21日
%%
sentence(L) :- jawiki(_,Node),getsentence(L,Node).
getsentence([],_).
getsentence([S|T],Node) :- lsearch(S,Node,Out),
format('~w ==> ~w ~n',[S,Out]),
getsentence(T,Node).
%getSentence(S,Node,Out) :- jawiki(_,Node),
% lsearch(S,Node,Out).
%% 見つかったら、node(A,B,S)を返す(改訂)
lsearch(S,node(A,S,B),node(A,S,B)).
% リストの場合
lsearch(S,node(A,[H|T],B),node(A,C,B)) :- getmember(S,[H|T]),
getlist([H|T],F),
flatten(F,G),
atomic_list_concat(G,C).
% 上で一致しなかったら、左右のノードの内側を調べる
lsearch(S, node(_, Y, _), N) :- lsearch(S, Y, N).
lsearch(S, node(_, _, Z), N) :- lsearch(S, Z, N).
%% -----------------------
%% getlistは、リストが[語, カテゴリ]から構成されているのから、語だけのリストを作る
%% 一つのフレーズに複数の語があると
%% [[[語, カテゴリ],語],[語, カテゴリ]] などのように繋がってリスト化される
%% knpがカテゴリを出力しない場合は、語が単独になることもある
%% HeadとTailをから、それぞれの語を取り出して、結合したのを出力
%% -----------------------
getlist([H|[T]],[X1, X2]) :- getlist(H,X1),
getlist(T,X2),!.
%% 構造的に、Tailには、単位リストしか入っていない
getlist([H|[T]],[H,H1]) :- atom(H),[H1|_] = T,!.
%% tailがリストでない場合は、atomであるHeadのチェック
getlist([H|[_]],H) :- atom(H).
%% tailが構造化されたリストの場合にはここで処理する
getlist([H|[T]],[Z,T]) :- atom(T),
getlist(H,Z).
%% -----------------------
%% 直下のリストのHeadに入っていればそれでよし
getmember(X,[X|_]).
%% アトムになったら失敗
getmember(_,[H|_]) :- atom(H),fail.
%% 直下になければ、その直下のHeadのリストの下に無いか再帰的に調べる
getmember(X,[H|_]) :- getmember(X,H).
このプログラムに基づいて、次のような処理をさせる。
?- sentence([これ,ロボット,持た,行動]). これ ==> node(に,これ,[基づいた,基づく]) ロボット ==> node(は,ロボット,node(を,node(いわゆる,[],[脳,動物-部位]),node(にも,[[持た,持つ],ない],node(かの,node([],node(ず,[関わら,関わる],まるで),[[生きて,生きる],いる]),node(に,よう,node([],[[行動,抽象物],する],[])))))) 持た ==> node(にも,持たない,node(かの,node([],node(ず,[関わら,関わる],まるで),[[生きて,生きる],いる]),node(に,よう,node([],[[行動,抽象物],する],[])))) 行動 ==> node([],行動する,[]) true
swi-prologで実行している。ゴール sentenceの引数として、検索キーワードのリストを与えている。これらすべてのキーワードを抱えている二分木が引っかかってくる。プログラムは、引っかかった後のノードを出力するようにしている。
厳密にいうと、そのキーワードよりも深いところを構成する部分木を出力させている。
画像にあるように「これ」というキーワードは、最下層のノードにぶら下がっているので、その最下層の部分木だけが出力される。逆にロボットは、最も上位のノードにぶら下がっているので、右の部分木全体を出力している。
「これに基づく」という表現は、我々が日常的に使う表現であり、私がいう部分知識というものの最も小さい単位である。また、「行動する」も、行動という名詞が、するという補助語につながっている、小さい部分知識である。一方「ロボットは、いわゆる脳を持たないにも関わらず、まるで生きているかのように行動する」という表現は、部分知識ではあるが、かなりまとまった知識となっている。
この辺りの違いが重要な意味を持っている。