ディープラーニングで、名詞と名詞(ないしは動詞)をつなぐ助詞を選択させる試みの中間報告となる。数量的な結果はある程度出たので、メモがわりに書いておこうということである。
すでに示してある、名詞+助詞1+名詞/動詞+助詞2というフレーズのうち、助詞1以外の語から、助詞1を選択するというのが問題である。日本語ウィキペディアから1200万個くらいのこの4語のデータを作ったのだが、このうちの100万語を使って、自己符号器型のディープラーニングニューラルネットを学習させた。
ネットワークのトポロジーは、 563 500 400 300 156 となっている。左から入力ユニット(名詞二つのword2vecベクトル、200x2プラス、選択された助詞2、163個の広い出された助詞のうち、使われたものだけが1になっている。これらが入力データ)で、一番右が出力ユニット数(拾われた助詞1の総数163個のうち、実際に使われていたものだがけが1になっているベクトル)
テストはまだ行っていないのだが、データに対して、どれほどの答えを出しているのかを調べてみた。
結果は、10万個のデータに対して、53.6%の正解を示していた。正解は、選択肢の中で、最大出力が解答と同じである場合である。
じっさい、これには正しい答えというのは、あるようでない。「の」が「は」に変わっても大して意味が変わらないこともあるだろう。他の三つの語が同じでも、助詞はいろいろに変わりうるからだ。
政界のユニットが出力している値のヒストグラムは次の図のようになる。横軸が回答ユニットの出力値の幅で、縦軸がその範囲にある頻度である。
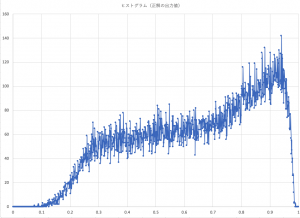
結果をパラパラ見る限り、使えそうな気はしている。教師データを100万個から500万個くらいにあげれば、もっと言いあてるようになると思う。1000万個まで行きたいが、とてつもなく時間がかかってしまう(ただ、この間、ディープラーニングのアルゴリズムやクラス構成、プログラム自体を改良していたのは、教師データを引き上げても、かかる時間以外の、メモリーなどで対応できるようにするためだったのだが)
まあ、まあ、こんなもんだなと言う感じである。実際、どのような文脈で、どのような助詞が選ばれるかについてテストした結果は(まだテストしてないが)、次の記事にする。