オートエンコーダーなどのディープラーニングは、元のニューラルネットワークが、勾配喪失や過学習の問題で行き詰ってしまったのを打ち破ったものだった。実際、私も、その有効性を確認できた。ただ、ひとつひとつの隠れ層の事前学習を過剰にやると、問題も起こってくることもわかった。
例えば、先の記事にも書いたが、入力層と出力層以外に、隠れ層の数を3層にして、それぞれのニューロン数を600、400、300にして、隠れ層の事前学習も、60000個の文字を一通りやるだけにする。すると、事前学習は収束しないのだが、Autoencoderののちに実施したテストでは、96%の正解率に上昇した。しかし、これで、各隠れ層の事前学習を収束するまで徹底的にやるとどうなるか。ここでは、ひとつの層を通常6万回のところを、それをさらに六回繰り返して、36万回データを使って事前学習させたら、正解率が88.7%まで落ちてしまったのだ。
これだと、ああ、事前学習も過学習に陥るのだな、ということになる。
しかし、実はそう単純なことではないのだ。そのことを見るために次の図を示す。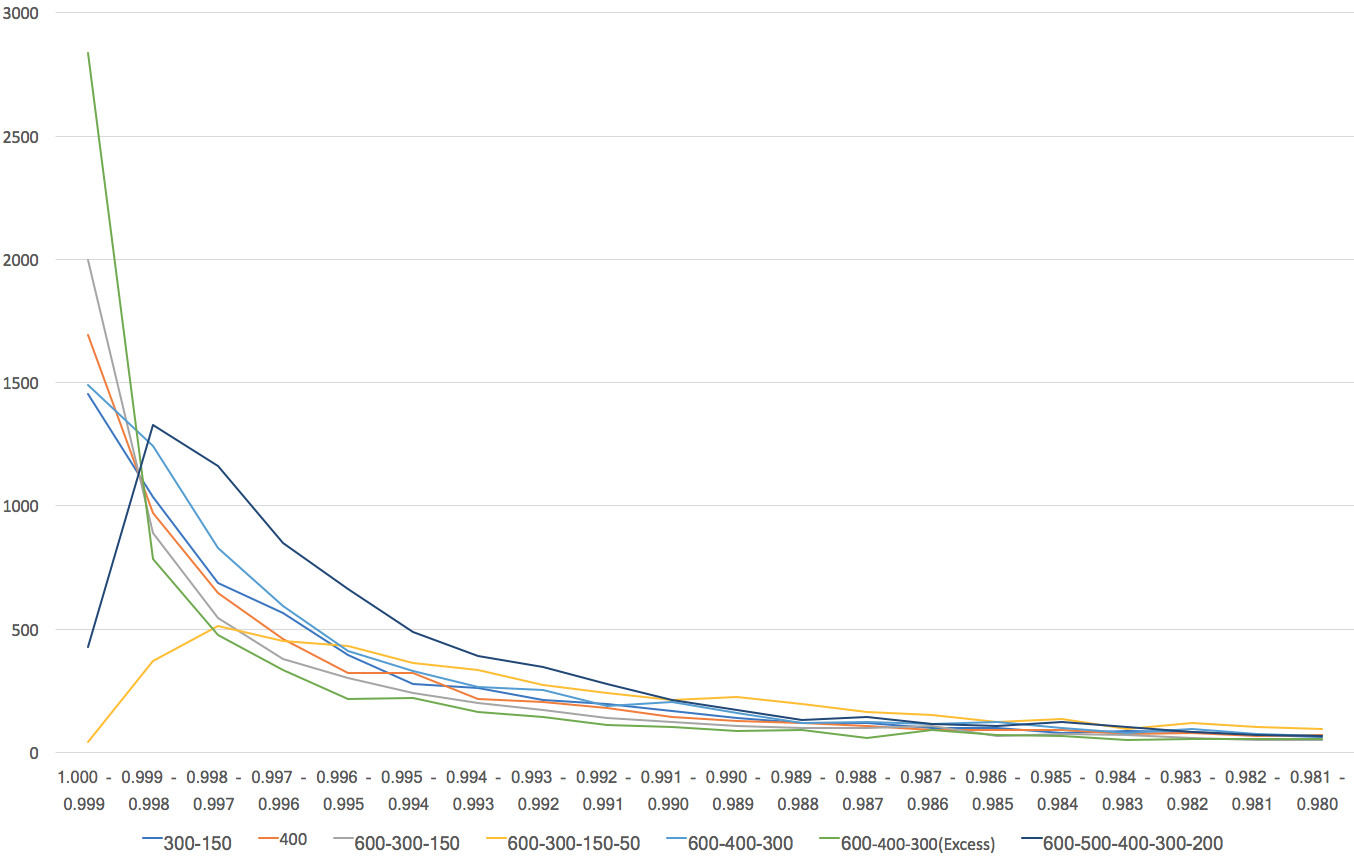
この図で、緑色の線が、Autoencoderで過度に学習させた先のネットワークだ。驚くべきことに、正解した出力ユニットの出力値が3000近くが0.999以上(最大値は1.0)で出力しているのだ。
つまり、自分が正しいと判定したことに強い確信を持っているということだ。あるいは、せいか率を犠牲にしても、そういう確信を持ちたがるネットワークだと言って良い。これに対して、過度に学習させなかったものは、正解率は高いが、だいたいそうだろう、という感じで答えを出してきていることがわかる。
結局、ネットワークに個性が出てきたのだ。正解ということに確信を持ちたいというネットワークと、いやいや、だいたいそうだろうと答えるタイプのネットワークが現れたことになる。
問題は、応用の場合、ロボットの小脳としてどちらのタイプのネットワークを使うべきかということだ。