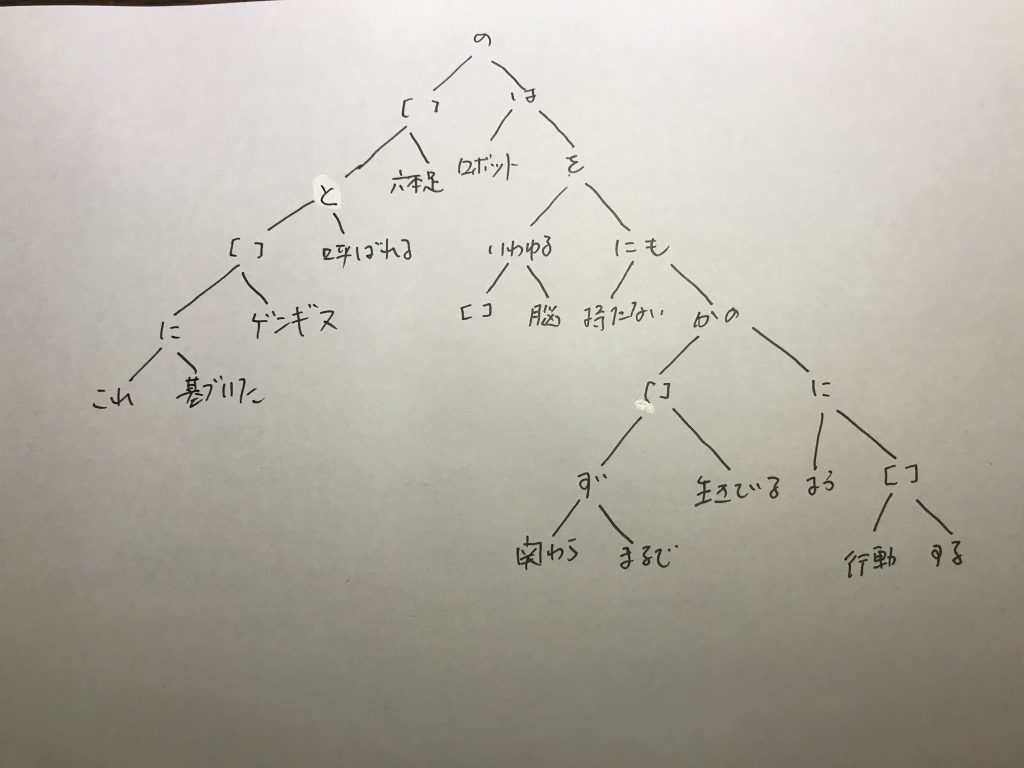
prolog二分木から初歩的な文章を作るようになったが、少しフォーマットを変更することにした。
一つは、動詞の原形を入れるときに、使われている表現形と同じ場合は、原形情報を与えなかったが、これを与えることにした。動詞と分かれば、原形がなければそれが原形と推測できるが、そもそも二分木には品詞情報を入れていないので、判断できないからだ。
なぜ、これが大事なのかといえば、動詞の原形は、それだけで文章終端になりうるからだ。文章を作るときに、終端が違和感なく終わることはとても大事なのである。このように「だ」「です」「である」などは、多分判定詞で、同士ではないが、例えば「書き」で終わったら、言葉としておかしいが「書く」で終わることは不自然ではない。だから、動詞の原形はとても重要なので、原形がある場合とない場合がはっきりしないというのは、良くないということで、改良した。
もう一つは、動詞の原形と名詞のカテゴリは、ほとんど同じフォーマットで入れ込んでいるが、ときに区別できなくなるときがあるので、それらの冒頭に、名詞のカテゴリの場合は「C:」というヘッダ、動詞の原形の場合は「V:」というヘッダーをつけることにした。例えば、次のようである。
jawiki(wiki_543_line_2261_1,node(を,小田,node([],[含む, 'V:含む'],node(は,['4', [名, 'C:抽象物']],node(に,node([],node(ばかりの,node(が,[放送, 'C:抽象物'],[[終了, 'C:抽象物'], [した, 'V:する']]),[アニメ, 'C:抽象物']),[[[機動, 'C:抽象物'], [戦士, 'C:人']], ガンダム]),node([],[[[熱中, 'C:抽象物'], [して, 'V:する']], おり],node(の,node([],node([],node(に,node(から,node([],node(が,node([],まだ,ガンプラ),[[[発売, 'C:抽象物'], [さ, 'V:する']], れる]),前),[同, [作品, 'C:抽象物']]),[[登場, 'C:抽象物'], [する, 'V:する']]),[[ロボット, 'C:人工物-その他'], [兵器, 'C:人工物-その他']]),'モビルスーツ(MS)'),node(を,[模型, 'C:人工物-その他'],node([],[[[自作, 'C:人工物-その他'], [して, 'V:する']], いた],[ ]))))))))).
二分木を一行にしているので少しわかりにくいのでインデントをつけて表すと次のようになる。
jawiki(wiki_543_line_2261_1,
node(を,
小田,
node([],
[含む, 'V:含む'],
node(は,
['4', [名, 'C:抽象物']],
node(に,
node([],
node(ばかりの,
node(が,
[放送, 'C:抽象物'],
[[終了, 'C:抽象物'], [した, 'V:する']]
),
[アニメ, 'C:抽象物']
),
[[[機動, 'C:抽象物'], [戦士, 'C:人']], ガンダム]
),
node([],
[[[熱中, 'C:抽象物'], [して, 'V:する']], おり],
node(の,
node([],
node([],
node(に,
node(から,
node([],
node(が,
node([],
まだ,
ガンプラ
),
[[[発売, 'C:抽象物'], [さ, 'V:する']], れる]
),
前
),
[同, [作品, 'C:抽象物']]
),
[[登場, 'C:抽象物'], [する, 'V:する']]
),
[[ロボット, 'C:人工物-その他'], [兵器, 'C:人工物-その他']]
),
'モビルスーツ(MS)'
),
node(を,
[模型, 'C:人工物-その他'],
node([],
[[[自作, 'C:人工物-その他'], [して, 'V:する']], いた],
[ ]
)
)
)
)
)
)
)
)
).
これで、例えば、最初の「含む」は、原形と表現形が同じだが、原形を付加している。また、動詞なのでヘッダにV:が付いている。これで、処理がよりしやすくなった。
これで、一昨日から、日本語wikipedia本文とツイッターデータを全部作り直している。