前の記事では、仮想的文章をprolog化することを示したが、実際の文章を与えてprolog化するJAVAプログラムを作成した。以下から、ダウンロードして実行できる。
https://github.com/toyowa/JProlog
ただし、cabochaが必要なので、そのREADMEテキストの指示に従って呼び出せるようにする必要がある。
これまでも例に使ったwikipediaの芸人の定義文書をprolog化する。
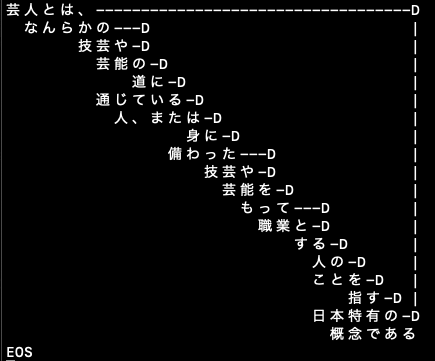
「芸人とは、なんらかの技芸や芸能の道に通じている人、または身に備わった技芸や芸能をもって職業とする人のことを指す日本特有の概念である」
まず、cabochaで、フレーズに分解すると次のようになる(JAVAプログラム出力の一部)。
%% ------ フレーズリスト ---------
% 助詞・助動詞,名詞・動詞,接続詞,原型
% No.0: とは, 芸人, ,
% No.1: , [[なんらかの], 技芸], や,
% No.2: の, 芸能, ,
% No.3: に, 道, ,
% No.4: , 通じ, ている, 通じる
% No.5: , 人, または,
% No.6: に, 身, ,
% No.7: た, 備わっ, , 備わる
% No.8: , 技芸, や,
% No.9: を, 芸能, ,
% No.10: , もっ, て, もつ
% No.11: と, 職業, ,
% No.12: [ところの,という], する, , する
% No.13: の, 人, ,
% No.14: を, こと, ,
% No.15: [ところの,という], 指す, , 指す
% No.16: の, 日本特有, ,
% No.17: である, 概念, ,
%%--------------------------------
ただし、これまでと少し改定した点は、cabocha(あるいは、mecab)の助詞の第二品詞が「副助詞/並立助詞/終助詞」、「接続助詞」、「並列助詞」を助詞ではなく、接続詞扱いしている点にある(詳細な手続きは、プログラムを見ていただきたい)。その理由は、ここでの目的は、文章の中にある部分知識を得ることで、その点で、接続詞の前後が部分知識になっている可能性が高いからである。
その視点から、フレーズリストをリストに構造化すると次のようになる(JAVAプログラム出力の一部)。
[ [ 0 1 2 r3 ] r4 [ r5 [ 6 7 r8 [ 9 r10 [ 11 12 13 r14 15 16 17 ] ] ] ] ]
rのついたフレーズ番号は、その部分リストのルートフレーズである(この辺りはこれまでの記事で解説ずみ)。ルールとしてフレーズが3個より短いサブリストは作らないことにした。
重要な点は、通常助詞よりも、接続詞をルートフレーズ化する場合の優先度を高めた。つまり、接続詞があれば、それを助詞よりも優先的にルートフレーズかするということである。
サブリストも含めたルートフレーズは、改めて具体的に表示すると、次のようになる。
%% ルート句: No.4 助詞/動詞: 語:通じ 接続詞:ている 原型:通じる
%% ルート句: No.3 助詞/動詞:に 語:道 接続詞: 原型:
%% ルート句: No.5 助詞/動詞: 語:人 接続詞:または 原型:
%% ルート句: No.8 助詞/動詞: 語:技芸 接続詞:や 原型:
%% ルート句: No.10 助詞/動詞: 語:もっ 接続詞:て 原型:もつ
%% ルート句: No.14 助詞/動詞:を 語:こと 接続詞: 原型:
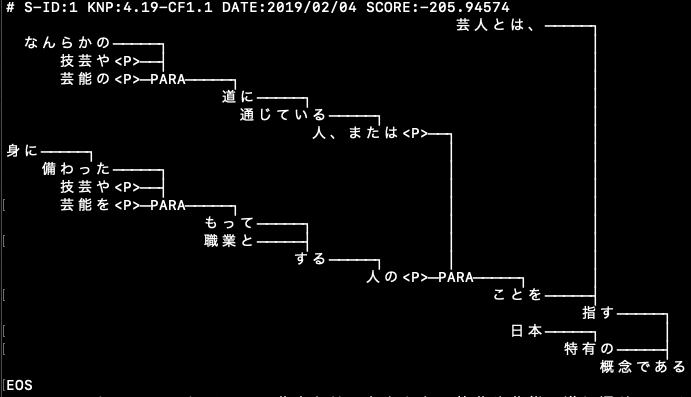
これを先の記事で示したツリー化と表示クラスに咥えこませると、次の結果を得る。
%% Prolog宣言
pl000(
node(ている,
node(に,
node(の,
node(や,
node(とは,
芸人,
[[なんらかの], 技芸]
),
芸能
),
道
),
通じ
),
node(または,
人,
node(や,
node(た,
node(に,
身,
備わっ
),
技芸
),
node(て,
node(を,
芸能,
もっ
),
node(を,
node(の,
node([ところの,という],
node(と,
職業,
する
),
人
),
こと
),
node([ところの,という],
指す,
node(の,
日本特有,
node(である,
概念,
[ ]
)
)
)
)
)
)
)
)
).
swiprologは、問題なく通過する。listingで表示させると、次のような1行になっている。
pl000(node(ている, node(に, node(の, node(や, node(とは, 芸人, [[なんらかの], 技芸]), 芸能), 道), 通じ), node(または, 人, node(や, node(た, node(に, 身, 備わっ), 技芸), node(て, node(を, 芸能, もっ), node(を, node(の, node([ところの, という], node(と, 職業, する), 人), こと), node([ところの, という], 指す, node(の, 日本特有, node(である, 概念, []))))))))).
以前の記事の出力結果と比べると大きく違っている。うねりが蛇のように複雑になった。それは、フレーズリストがサブリストの複雑な再帰的構造を持っている結果である。
われわれがもともと意識したというか、直感的に確実に持っている「または」という接続詞が二つの「人」を分けていることは表現できなかった。ここは、本当に文章の意味がわからなければ捉えられない。意識的にそのような構造をフレーズリストに反映させればそれは実ガン可能なのだが、今のところはそうしない。
右側の山の出っ張りのあたりに、この「芸人」の定義の大事な要素がにじみ出ている。その理由は、この山を小刻みに作っているのが、接続詞による分割が行われているためである。
また、「国境の長いトンネルを抜けると雪国であった」をprolog化すると次のようになる。
%% ------ フレーズリスト ---------
% 助詞・助動詞,名詞・動詞,接続詞,原型
% No.0: の, 国境, ,
% No.1: を, [[長い], トンネル], ,
% No.2: , 抜ける, と, 抜ける
% No.3: であった, 雪国, ,
%%--------------------------------
%% 「国境の長いトンネルを抜けると雪国であった」のprolog化
%%--------------------------------
%% ルート句: No.1 助詞/動詞:を 語:[[長い], トンネル] 接続詞: 原型:
%% フレーズ番号リスト = [ 0 r1 2 3 ]
%% Prolog宣言
pl000(
node(を,
node(の,
国境,
[[長い], トンネル]
),
node(と,
抜ける,
node(であった,
雪国,
[ ]
)
)
)
).
こちらは、これまでとほぼ同じ結果になる。接続詞が一つもないからである。
課題としては、次のようなものがある。(1)接続詞を無条件にルート化するというのは、やや無謀だ。(2)「は」とか「とは」は、接続詞よりも高めたほうがいい。(3)あっさり、プライオリティー水準をいろいろな基準で作ったほうがいいかもしれない。