オリジナルなHikey970のubuntu、つまりlebuntuは全く日本語環境が入っていないので、前の記事ではubuntu18.04を入れるとか言っていたが、実はそれはとても難しく、私にはできそうになかった。
そこで、lebuntuに追加で日本語環境をインストールすることにした。フォントなどをインストールしたら、日本語は表示できるようになったし、localeをLANGでja_JP.UTF-8にしたら、出力が日本語になって使いやすくなった。
しかし、日本語の入力はいまだにできない。悩ましい。
オリジナルなHikey970のubuntu、つまりlebuntuは全く日本語環境が入っていないので、前の記事ではubuntu18.04を入れるとか言っていたが、実はそれはとても難しく、私にはできそうになかった。
そこで、lebuntuに追加で日本語環境をインストールすることにした。フォントなどをインストールしたら、日本語は表示できるようになったし、localeをLANGでja_JP.UTF-8にしたら、出力が日本語になって使いやすくなった。
しかし、日本語の入力はいまだにできない。悩ましい。
ニューラルネットワーク処理ユニット(NPU)を持つシングルボードコンピュータを、スイッチサイエンス社から39,744円で購入した。アマゾンに出ている商品と同じものだが、ここが一番安かった。
ひたすら好奇心である。NPUというものは、どれほどのものだろうということである。ただし、UPUをのぞいでも、このコンピュータのスペックはとてもいい。
まだ、NPUをどうやって動かすのか、というか、プログラミングに組み込むのかということはわかっていないが、さしあたり、試しに、Ubuntu、LemakerのUbuntuという意味で、Lebuntuというらしい、を組み込んでみた。
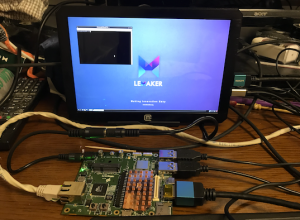
最終的には上記のようにlebuntuがスタートする。最大の弱点は、日本語環境が出てこないことだ。
インストールの仕方をメモがわりに記載する。
(1)Linux を用意する。
(2)このサイトから、lebuntuのimgファイル類をダウンロードする。
(3)rarファイルを解凍する。(ubuntuの場合、unrarが必要だった)
(4)その中に、lebuntu-rfs_flashing_guide.txtというドキュメントがあるので、そこに書いてある通りのことを実行すれば、インストールできる。その通り実行しないと失敗する!!
以下注意点
(1)INSTALLING BINARIES(only new boards)とFLASHING Lebuntu 16.04 IMAGE ONLYの二回実行する。
(2)Hikey970のUSB-CとLinuxのUSB端子をつなぐ。
(3)MACのVirtualBoxに入れたLinuxでやったら失敗した。USBのつながりがダメなようだ。Linuxマシンを用意する。私の場合は、Intelのスティックコンピュータに入れたUbuntuにつないで実行した。
特にないか。要は、先のマニュアル通りのことができればOKなのだ。
ただ、Lebuntuでは、日本語が使えない(使い方があるのかもしれないがわからない)ので、今度、正式のUbuntu 18.04をインストールしようと思う。
NPUは、Hikey970 with pre-built Tensorflowというのがあるので、そちらのimgを焼くことで実現するのだと思う。
要は、MapのListをMapのあるValue順にソートするということだけれど、答えはこちらのサイトで教えていただきました。
Collections.sort(maplist, new Comparator<Map<String, String>>(){
@Override
public int compare(Map<String, String> rec1, Map<String, String> rec2) {
String colName1 = rec1.get("pubDate");
String colName2 = rec2.get("pubDate");
return colName2.compareTo(colName1);
}
});
以前、スティックコンピュータで、mariadbのデータフォルダをmicroSDに移したという話を書いたが、その時は、my.cnfの設定を変更したものだった。今回、VPSのmariadbはそれでも簡単にいかなかったので、新しいフォルダ/data/mysqlに、/var/lib/mysqlからのシンボリックリンクを貼ってやってみた。難なく、それだけで、全て片付いた。これが一番楽チンだ。以下の方法は、CentOS用です。他は、コマンドが違うかも。
(1)mysql (mariadb) を止める ← 重要
(3)新しいフォルダを作成しオーナーを変更する
sudo chown mysql:mysql /data/mysql
(3)新しいフォルダーに全部コピーする
sudo cp -pr /var/lib/mysql/* /data/mysql/
(4)元のフォルダーをrenameして使えなくしておく(万が一のために元に戻せるように)
(5)シンボリックリンクを貼る
sudo ln -s /data/mysql/ /var/lib/mysql
とこうなる。
lrwxrwxrwx 1 root root 12 11月 23 15:35 2018 mysql -> /data/mysql/
(6)mysql (mariadb) を再スタートする
何もかも、Java頼みだ。ロボット即興漫才のシステムは、ロボット内のシステム(ライブラリ)は、C++、コントローラーはHtml5(Javascript)、アプリケーションレベルは全てJavaだ。
JavaとHtml5の開発は、Netbeans頼みなのだ。久しぶりにバージョンアップした。apacheからダウンロードするようになった。これからは、apacheのnetbeansに慣れていかなければならないので、使うようにしようということだ。
https://netbeans.apache.org/download/index.html
ここからダウンロードしてインストールすれば良い。私の場合、macなので、少し違っているが、
https://github.com/carljmosca/netbeans-macos-bundle
から、ダウンロードして、スクリプトを実行すれば、今までにない、カラフルなnetbeansのスプラッシュが現れて実行される。
外に借りているVPSサーバーにmariadbが入れてある(何を隠そう、このサイトは、このVPSに載せてある。格安でありながら、結構使い勝手がいいので気に入っている)。ただ、バージョンは古く、MariaDB-server-5.5.60である。10.3とかにすればいいのかもしれないが、問題は、先に作ったtwitterの頻度データをそこに載せる必要があったのだが、パソコンで作ったデータベースをdumpして、移行しようとしたら、リストアするときに、
Index column size too large. The maximum column size is 767 bytes
というエラーで止まってしまうのだ。インデクスのサイズが小さすぎるらしいが、ネットにあるいろいろな対応を試みたが、うまくいかなかった。
最終的にどうしたかだけ、いや、多分この操作が良かったのだろうというところだけ書いておく。
ちなみにVPSは、CentOs の6.9あたりが入っている。これもあまり新しくない。今更、バージョンアップするのも面倒だ。
さしあたって、https://blog.cles.jp/item/9965に書いていただいているような対応をする(参考にさせていただいて感謝します)。要は、/etc/my.cnf.d/server.cnfに、
[mysqld] innodb_file_format = Barracuda innodb_file_per_table = 1 innodb_large_prefix = on innodb_default_row_format = DYNAMIC # この設定が効かない場合には以下を参照
を書き加えるのだ。が、私の場合、最後の文章を入れてmariadbを再起動すると、失敗した。したがって、これは、入れることができない。ありがたいことに、それがダメな場合はというコメントで、以下のようにするといいと書いてある。
CREATE TABLE `hogetable` ( id INT(10) UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY, ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 ROW_FORMAT=DYNAMIC;
ところが、私の場合、テーブルを作るのではなく、ダンプしたものをリストアするのであるから、このような、テーブルを作るプロセスそのものはない。ダンプの仕方を色々変えてもやってみた。indexを抜いた形でdumpして、リストアして、その後、indexを作成したりもしたが、結局同じエラーが出る。
indexを抜けば、普通にリストアできるが、index抜きで使ったら数百万のデータを検索する時間は、ほぼ使い物にならないくらいかかってしまう。
結局、150メガもあるだぷファイルの中身を見ることにした。すると、それはテキストファイルで、全てのデータベース操作がそこに書いてあるものなのだ。そして冒頭に、次のような、テーブルを作成するコマンドが書かれていた。
CREATE TABLE `tweetedwords` ( `word` varchar(200) NOT NULL, `part` varchar(5) NOT NULL, `frequency` int(15) NOT NULL, KEY `twitterword` (`word`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
なんだ、そうか!という感じだ。ここに、先に教えてもらった ROW_FORMAT=DYNAMICを書き込んだら、見事、リストアできた。つまり
CREATE TABLE `tweetedwords` ( `word` varchar(200) NOT NULL, `part` varchar(5) NOT NULL, `frequency` int(15) NOT NULL, KEY `twitterword` (`word`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 ROW_FORMAT=DYNAMIC;
と変更しただけである。
良かった、良かった。
去年の12月から間を開けながらボツボツと集めたツイートが今日の時点で、55,227,803ツイート、ファイルサイズにして738Mbになった。プロセス1個で集めている。プロセスを増やしても、ツイッターアプリ経由で捉えられる(ツイッター社がサンプルで配信する)ツイートは同じものであるので無駄なのだ。地道に集めるしかない。プロセス増やしても、たくさん集まった気になるだけで中身は、単なる水ぶくれになる。プロセスは1個しかダメなのだ。
でも、まあ、ほぼ1年動かしているので、季節による言葉の方よりはだいぶなくなっていると思うので、ここらあたりで締めようと思う。ただ、ツイートの取得はずっと続けていくつもりだ。
1億を目指している。キリがいいので。
当面やりたいのは、ツイッターで使われている単語の頻度を分析することだ。
以前まで正常に動いていたphpMyAdminが突然動かなくなった。phpファイルを生で表示してしまう。apacheのphpモジュールの問題なのか色々探ったが、解決しない。多分、OSが更改されたための問題のようだが、わからない。
apache2から起動するのを諦めて、phpのバージョン7が入っているので、その内蔵のウェッブサーバーから起動することにした。
やり方は簡単だ。phpMyAdminのシステムは、/Library/WebServer/Documents 以下においてあるので(http://www.ibot.co.jp/wpibot/?p=131 参照)そこで、
php -S localhost:8000
と打てば、phpの内臓サーバーが起動する。ブラウザでアドレス
http://localhost:8000/phpmyadmin/
を指定すれば良い。これ以外に、macのウェブサーバーを利用するつもりがないときは、これで十分だ。
上記については、以下のサイトを参考にさせていただいた。
https://qiita.com/masahirok_jp/items/c4f0d8bb5f55a114e31b
今までは、間違っているのに知ったかぶりをするボケと、ツッコミが乗ってしまうボケというのを利用していたが、反対語を挟んで間違うというボケも可能だと思った。反対語を言ってしまう天丼もあっていい。
今、サリーには、2万語以上のコンセプトが組み込めるようになっている。ただ、もう、絶対使わないだろうなというコンセプトも入っている。それは無駄だ。よく使いそうなコンセプトに入れ替えて、まあ、全体として2万語になればいい。
そのためのシステムなり、データベースが必要だ。潜在的可能性のあるコンセプトを貯めておいて、スコアを与え、スコアの高いものから順番に入れておくというのが望ましい。実際に、wikipediaとか、twitterで使われる頻度、辞書への掲載などの基準でスコア化する。もちろん、ライブでお客さんから出されたお題の場合は、さらにスコアを大きくすべきだろう。