半日かけて、ニューラルネットのプログラムをC++から、JAVAに書き換えた。
驚いた。学習のスピードが100倍以上速くなった。私のC++のプログラムが遅すぎるのか。書き方がおかしいのか。いや、そういうレベルの問題ではないくらいに、速くなった。
日別: 2017年6月2日
ニューラルネット、Javaで書き直す
ここまでC++でやっておいてなんだが、プログラム全体をJavaで書き直そうかと思っている。C++のスレッドが、なんだかうまく動かない。ニューラルネットに並列処理は不可欠なのだが、C++ではダメなような気がしてきた。
Javaも十分早くなったし、Javaでニューラルネットのパッケージも作られているくらいだから、RaspberryPIでもjavaは使えるので。そうなると、ロボットのコントローラー全部をjavaにしてしまうかもしれない。
自己符号化器, Autoencoderをニューラルネットに組み込む
スレッド問題は保留にして、ニューラルネットワークが、ほぼ予定通り機能しているような感じだから、ディープラーニングに進む。
画像認識ではなく、ロボットの動作制御に組み込むことを想定すると、いかに数少ないデータで効率の良い判断力をつけるかが問題となる。そういう点では、まず、基本的な自己符号化器を扱えるようにした方が良いと感じた。
自己符号化器は、元々の入力データが持っている特徴を際立たせる事前作業を行うことで、階層が深くなってもその力を活かせるようにしている。プログラミングとしては、ニューラルネット、バックプロパゲーションが組み込まれていれば、拡張は容易だ。
ただ、世間では、あまりこの自己符号化器は使われなくなっているようだが、目的に依存するだろう。
隠れ層のニューロンを400にしたら正解率が落ちた(笑)
MNISTを利用した他の研究を見ていると、私のように隠れ層が100ニューロンというのは例外的に小さい。そこで、隠れ層を400にして60000個の学習データでウェイトを学習させ、同じように10000個のテストをやって見た。
結果、
<正解数 = 9201 不正解数 = 799 正解率 = 0.9201>
で、正解率が1%落ちた(笑)
ただ、正解の時に、どのようなユニット出力になっているかを見ると、さすが隠れ層を増やした結果だなと思わせる。
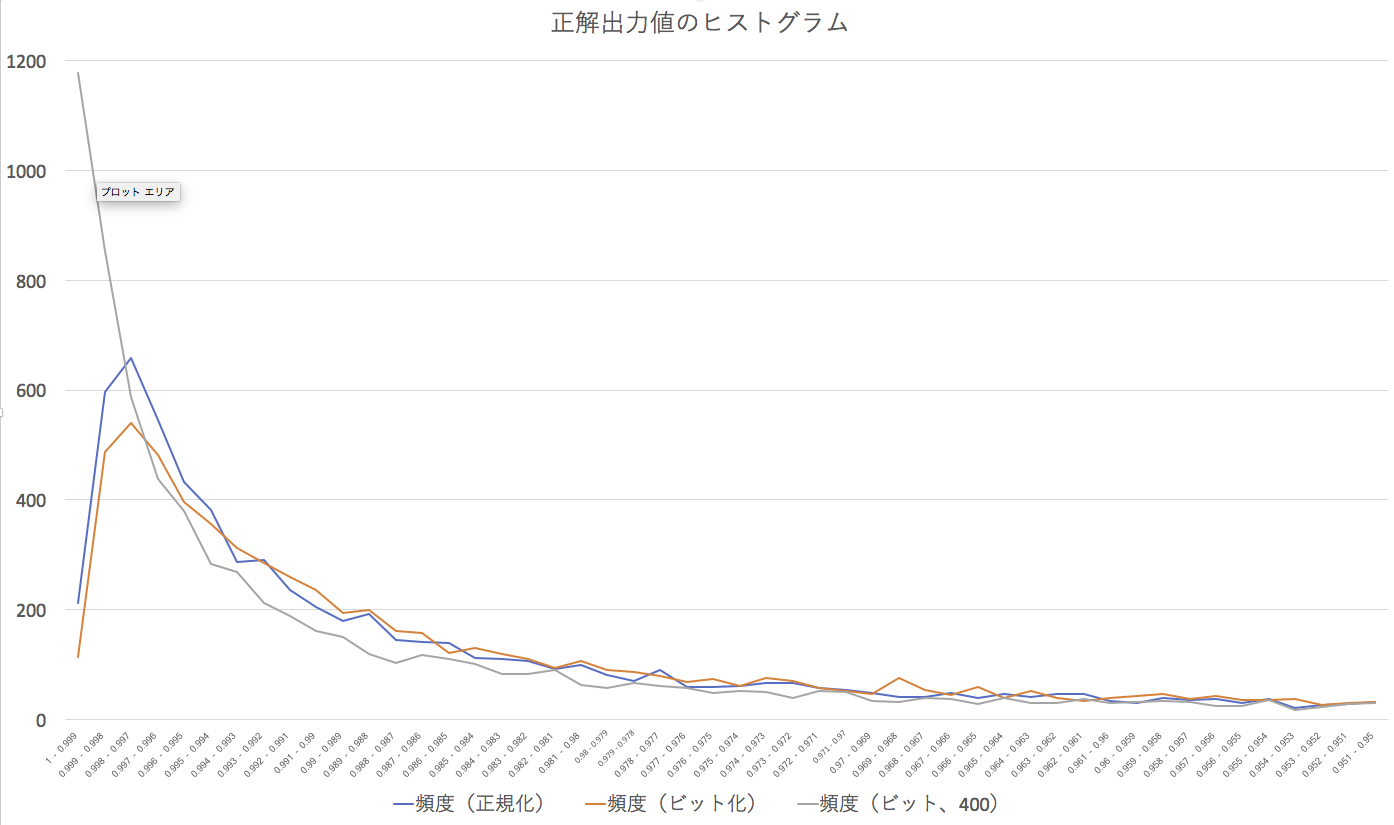
図を見てもらえば明らかなように、先の2つのケースに比べて、その数字のユニット出力が0.999以上、つまり、ほぼ1になっているのだ。認識した数字に対する確信が抜群に高いということだ。「これは間違いなく3だ」とか、ネットワークが言い放っているような感じだ。そのためか、若干汚い手書き文字に対して、厳密な態度を取っている「こんな数字4じゃないだろう!」みたいな上から目線といっても良い。しかし、認識率もそれほど落ちたわけではない。ただ、上昇しなかったのが悔しいだけだ。