ネタでは、セリフが冗長と感じさせないためには、セリフの語の長さをだいたい30語程度に抑えないといけない。
ロボットの即興漫才で、その場で与えられたお題に対してネタを作成する場合、あるいは、謎かけの答えを作る場合、自ら持っている様々な知識を駆使して台本にして行くのだが、知識から生成されるセリフが、それよりも長くなっている場合が少なくない。
どうやってそれを狩り込むか。9月の漫才の賞レースm-1では、「〜は」という冒頭から30文字のところで、ぶち切ってやった。これは無理があるので、改善しようということだ。
ここ2、3日色々考えて、ある文章を30文字にする技術は、結構難しい。たくさんの文章があって、その中から大事な文章を選び出して要約するというのはウェッブ上に色々情報があるが、単一文章を処理するというのは、情報が少ない。
菊池 悠太氏が、2016年、東京工業大学に提出した博士論文「 単一文書要約の高度化に関する研究」がある。まだ、ちょっとしか読んでいない。が、参考にさせていただいた。
そんな本格的なものを作ることはさしあたって保留しなければならない。そこでやったことは、簡単なものだ。例えば、肥満の定義が次のようにあったとしよう。
「肥満は一般的に、正常な状態に比べて体重が多い状況、あるいは体脂肪が過剰に蓄積した状況を言う」(wikipediaより)
45文字くらいある。最後は体言止めでいいので、「を言う」は無条件に削る。42文字で、12文字削らなければならない。
これを短くすることを考える。cabochaという自然言語の係り受け解析、構文解析ツールを使って、この文章をparseする。すると、こんな情報を得られる。
[0] => 11
肥満:名詞:サ変接続:*:*:*:*:肥満:ヒマン:ヒマン
は:助詞:係助詞:*:*:*:*:は:ハ:ワ
[1] => 10
一般的:名詞:固有名詞:一般:*:*:*:一般的:イッパンテキ:イッパンテキ
に:助詞:格助詞:一般:*:*:*:に:ニ:ニ
、:記号:読点:*:*:*:*:、:、:、
[2] => 3
正常:名詞:形容動詞語幹:*:*:*:*:正常:セイジョウ:セイジョー
な:助動詞:*:*:*:特殊・ダ:体言接続:だ:ナ:ナ
[3] => 4
状態:名詞:一般:*:*:*:*:状態:ジョウタイ:ジョータイ
に:助詞:格助詞:一般:*:*:*:に:ニ:ニ
[4] => 6
比べ:動詞:自立:*:*:一段:連用形:比べる:クラベ:クラベ
て:助詞:接続助詞:*:*:*:*:て:テ:テ
[5] => 6
体重:名詞:一般:*:*:*:*:体重:タイジュウ:タイジュー
が:助詞:格助詞:一般:*:*:*:が:ガ:ガ
[6] => 7
多い:形容詞:自立:*:*:形容詞・アウオ段:基本形:多い:オオイ:オーイ
[7] => 8
状況:名詞:一般:*:*:*:*:状況:ジョウキョウ:ジョーキョー
、:記号:読点:*:*:*:*:、:、:、
あるいは:接続詞:*:*:*:*:*:あるいは:アルイハ:アルイワ
[8] => 10
体脂肪:名詞:固有名詞:一般:*:*:*:体脂肪:タイシボウ:タイシボー
が:助詞:格助詞:一般:*:*:*:が:ガ:ガ
[9] => 10
過剰:名詞:形容動詞語幹:*:*:*:*:過剰:カジョウ:カジョー
に:助詞:副詞化:*:*:*:*:に:ニ:ニ
[10] => 11
蓄積:名詞:サ変接続:*:*:*:*:蓄積:チクセキ:チクセキ
し:動詞:自立:*:*:サ変・スル:連用形:する:シ:シ
た:助動詞:*:*:*:特殊・タ:基本形:た:タ:タ
[11] => -1
状況:名詞:一般:*:*:*:*:状況:ジョウキョウ:ジョーキョー
[ ]に入った番号が、句の番号で、矢印の後の数字は、その句がどの句にかかっているかを示している。その下にある情報は、句内の語の構文解析結果である。ここは、多分mecab を使っているのだと思う。ただし、この出力は、cabochaのそのままではなく、parseして、情報を組み直していることをご了解くださいね。こんな出力じゃないなって言わないで。
まず、述語を確定する。これは、主語の最終係り先である。[11]であり、そこが-1になっているのは、それ以上どこにもかかっていないということである。
さらに、どこまでいっても、述語にかからない句は無条件に削除する段取りだが、この文章に、そういう遊びのフレーズはないことがわかる。
そして最後にすることは、各句内の動詞や名詞の語が、主語とどれほど関係が深いかをword2vecという人工知能的ツールを使って分析する。word2vecは、このサイトのいたるところに書いているが、言葉を数字のベクトルに変換するものである。私の場合は、日本語wikipediaの全情報を処理したウェイトと、twitterの2千数百万ツイートを使ったウェイトの二つのデータ(どちらも膨大)を持っている。ウェイトは、200次元ベクトルである。つまり、数十万という言葉が、200次元の数値ベクトルで表されるのである。言語という、魑魅魍魎をベクトルにしてしまう。何という発想。そこは、特殊なニューラルベットワークになっている。
本当に、word2vecはすごいツールなのだが、この考え方やプログラムを無償で公開しているgoogleさんには感謝したい。
word2vecは、近い言葉探しに使われることが多いが、それよりも、与えられた言葉の親近度合い測るのに使うのが、至極便利なのだ。ロボット謎かけ生成でも、散々使った。
そのウェイトを使って、主語のウェイトと各句内にある名詞、動詞との関連性の強さを測って(ベクトル積をとって、平方根を取った)、関連性が弱いものから削っていくということである。
これは、本来、ナップサック問題として解くべきだが、ここでは単純に、文字数が30文字以内になるまで、関係の薄いくから順番に削っていくという方法にしている。
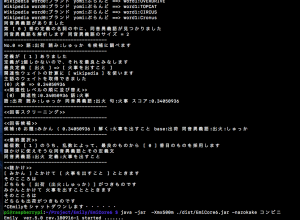
関連性ウェイトの計算に [ wikipedia ] を使います
主語のウェイトを取得できました
(0) 一般的 => 0.5375686
(1) 状態 => 0.4457973
(2) 比べる => 0.39656168
(3) 体重 => 0.67140776
(4) 状況 => 0.4373728
(5) 体脂肪 => 0.6685157
(6) 蓄積 => 0.49764314
(7) する => 0.24754475
<<関連性レベルの順に並び替え>>
(0) 関連性:0.67140776 語:体重
(1) 関連性:0.6685157 語:体脂肪
(2) 関連性:0.5375686 語:一般的
(3) 関連性:0.49764314 語:蓄積
(4) 関連性:0.4457973 語:状態
(5) 関連性:0.4373728 語:状況
(6) 関連性:0.39656168 語:比べる
(7) 関連性:0.24754475 語:する
これが結果で、後半部は、ウェイトの大きな順に並び替えるようにしている。肥満に最も関連性の強い言葉は、体重である。OK!OK!いいじゃない。実に妥当な計算結果になっている。
これで削るのであるが(1)主語は削ってはならない!(2)述語も削ってはならない!(3)同じくに二つのウェイトを持った語がある場合は、そのウェイトの大きな語を尊重しなけばならない。この三つのルールで、句の削除を行った結果は次のようになる。
---------------------------------------------
No.4 [ 比べて ] を削減します
No.7 [ 状況、あるいは ] を削減します
No.3 [ 状態に ] を削減します
**** 目標の長さになるまで削減しました 長さ = 29 ****
縮減された文章
肥満は一般的に、正常な体重が多い体脂肪が過剰に蓄積した状況
というわけで、
「肥満は一般的に、正常な状態に比べて体重が多い状況、あるいは体脂肪が過剰に蓄積した状況を言う」
を30字以内に要約すると、
「肥満は一般的に、正常な体重が多い体脂肪が過剰に蓄積した状況」
となる。
日本語の文法的には、「多い」を「多く」に変えるだけで、全く問題なく、ほとんどの情報を失わず、短くなっている。結局、何を削除するのかという問題である。ここに、人工知能的手法が必要なのである。