今までは、間違っているのに知ったかぶりをするボケと、ツッコミが乗ってしまうボケというのを利用していたが、反対語を挟んで間違うというボケも可能だと思った。反対語を言ってしまう天丼もあっていい。
カテゴリー: ロボット漫才
Qichatでヴァーチャルなif文を作る(1)
(※ 次の(2)で、単純に説明します、笑)
ロボットは対話で動かすというのが、私の確信だ。NAOを動かすときは、基本Qichatで書かれたtopicファイルに、自作ライブラリを起動するための独自コマンドを埋め込んで、制御する。
この間、一つのスクリプトで、即興漫才と即興謎かけのネタを切り替えるようにした。このスクリプトは、お題として識別できる語数は20000万語を超えている。それも、Qichatに書かれている。
ここで問題は、Qichatの変数 $manzai の値が1の時は、もらったお題に対して即興漫才を実行し、それが0の時は謎かけをするようにしたい。しかも、お題として認識できるのは、標準でこれまで作成したコンセプト2500語に引っかかるのか、その後拡張した18000 語の方に引っかかるのかということがある。混ぜていないのだ。
当初は以下のような書き方をしていた。
u:(お題は _~manzai_concepts です) $manzai==1 $1 ですね。少しお待ちください。 $sub_main=$1 $telepathy_to_emily="emily_getmanzai_subjects/$sub_main" u:(お題は _~manzai_extended_concepts です) $manzai==1 $1 ですね。少しお待ちください。 $sub_main=$1 $telepathy_to_emily="emily_getmanzai_subjects/$sub_main" u:(お題は _~manzai_concepts です) $manzai==0 $1 ですね。少しお待ちください。 $sub_main=$1 $telepathy_to_emily="emily_getnazokake_subjects/$sub_main" u:(お題は _~manzai_extended_concepts です) $manzai==0 $1 ですね。少しお待ちください。 $sub_main=$1 $telepathy_to_emily="emily_getnazokake_subjects/$sub_main"
ロボットの出力文の中に、条件式を入れている。何が違うんだということになるかもしれない。$telepathy_to_emilyというのは、私のライブラリ ibotライブラリのコマンドであり、emilyというのは制御コンピュータの名前で、それに対してお題を送っている。コンピューターからは、作られたネタの要素がこれも、telepathyコマンド(Qichat的にいうとイベント)で返されてくるのだが。つまり、私のibotシステムでは、ロボットとロボット、ロボットとコンピュータの、ローカルネットを経由したやり取りは、すべてテレパシー機能として実現している。それで、お互いのデータのやり取りも2000バイトまでは日本語でもできるようになっているのだ。
Qichatに戻ろう。後の二つが謎かけの、標準コンセプトと拡張コンセプトの場合である。$manzai==1というのは、$manzaiの値が1の時だけ真となる。
Quichatのロボット出力に、一つでも真でないものがあると、その全体が出力しないという機能を使っている。$manzaiが1の時は、前二つのいずれかにマッチングし、そうでない時は、謎かけの後者二つのいずれかにマッチングするはずだった。
しかし、これはうまく機能しないかった。細かくは調べていないが、考えられるのは、Qichatは、マッチングしているイベント処理ステートメントのどれか一つでも偽の文があると、たとえ真の文があってもそれを実行しないということだ。
たとえば「お題はチューリップです」という拡張コンセプトのチューリップに一致した入力文(イベント文)が、漫才と謎かけで二つある。$manzaiが1ならば、漫才の文にだけ一致すると思うのだが、全体が偽となって、実行しなくなってしまうということだと思う。
そこで、まず、次のように改良した。
u:(お題は _~manzai_concepts です) $1 ですね。少しお待ちください。 $sub_main=$1 [ $getmanzai_script=1 $getnazokake_script=1 ] u:(お題は _~manzai_extended_concepts です) $1 ですね。少しお待ちください。 $sub_main=$1 [ $getmanzai_script=1 $getnazokake_script=1] u:(e:getmanzai_script) $manzai==1 $telepathy_to_emily="emily_getmanzai_subjects/$sub_main" u:(e:getnazokake_script) $manzai==0 $telepathy_to_emily="emily_getnazokake_subjects/$sub_main"
ポイントは、初めのロボット出力文の最後に、オプション処理の [ ] でくくっって、のちの、テレパシー送信文の漫才と謎かけのいずれかを実行するようにしたのだ。
これでいいかと思った。実際、ちゃんと謎かけのお題を与えると、パソコンにデータを送信し、回答をもらうようになった。そして、ネタ見せもこれでやった。
ただ、問題があることもすぐにわかった。たとえば、漫才の一つ目のお題をもらって実行する。それはちゃんとやる。しかし、それを終えて、もう一つお題をもらう。すると、「〇〇ですね、少しお待ちください」と言ったあと黙ってしまうのだ。そういう時は、もう一度お題を伝えると、今度はちゃんとテレパシーを送ってパソコンからの回答ももらう。
それで、さっき原因がわかった。 [ ] のオプションオペレータを使ったからなのだ。つまり[ ]がロボットの出力に与えられると、実行するたびに、一つずつ変わるようになっている。だから、最初のお題は、漫才用に対応するが、次にまたお題をもらうと、次の謎かけの処理をしてしまうのだ。
結局!!この [ ] を外したら思う通りの処理するようになった。 [ ]を外すと、選択せずに毎回両方実行する。その先のイベント処理の出力の中に、真があろうが偽があろうが関係なしに実行するのだ。だから、$manzaiが1の時は、つねに偽になっている、謎かけは実行されずに、漫才の処理だけが実行されるのだ。
あまりに単純なことで、笑ってしまいそうなくらいだった。
NAOの認識コンセプトの上限
サリーやマリーが、即興漫才や謎かけのお題を取得するのは、音声認識機能を使うが、クラウドを全く使わないので、全てローカルでやっている。googleのクラウドなんかも使えなくはないのだが、テレビのスタジオやライブの舞台にネットが繋がるとは限らない。テレビの収録では、ほぼ期待できない。そういうことがわかっているのに、クラウドでしか音声認識ができないというのは、馬鹿げた戦略である。
ローカルでNAOがお題を認識するためには、qichatのconceptを使う。この夏までは、コンセプトに2千数百個を入れて、お客さんのお題に対応していた。少ない。そこで、システムを変えて、日本語wikipediaや数千万のツイートを使って、自力でネタをその場で生成するシステムに変更し、お題の認識可能性も8000語に増やした。それが、10月の初め。
さらに今日、AI的手法で、ウィキペディアやツイートから取得した関連語20000語を識別させようと入力したら、認識のための音素にコンパイルするのに3分以上かかったが、できたのだ。ちゃんと認識する。
NAOのコンピュータは相当古いが、ネタに必要な自作ライブラリやスマホからコントロールするためのHTML5関係のファイルしか入れていないので、メインメモリにもディスクにも比較的余裕があった、ので可能になったのではないかと思っている。
今、実際のネタ作りは、同じローカルネット内のパソコンにお題を送って作成させている。インターネットにつなぐ必要はなく、サリーとマリーとパソコンがローカルネットに繋がっていれば良いので、閉鎖空間でも対応できる。
何れにしても、今日はNAOが2万語以上も識別可能性を持っていることにただ驚愕した。下手すれば、メモリのある限り認識するのではないか。上限が推測できない。まだまだいけそうな気はする。
(その後、2万3千語あたりが、実質的限界であることがわかってきた。それ以上にすると、コンピュータの実行速度が低下する。メモリの誓約だと思われる 2018年11月24日追記)
スティックコンピュータにミニディスプレイをつけた

ミニディスプレイをつけた。解像度は、高くても対応できるのだけれど字が小さくて見えなくなるので、800X600にしている。キーボードとマウスは、その両者ついているbluetoothのミニパッドがつながる。
あとは、sshを有効にして、パソコンからコントールできる。
ディープラーニングによる日本語の助詞の選択(2)
先に助詞の使い方を学ばせたAI(ディープラーニングさせたニューラルネットワークというのが長いので、単にこう言うことにする)に与えられたフレーズの中の一つの助詞を選択させた。その一部を下に示している。助詞そのものは、160フレーズくらい取り上げているが、実際には、データの少ない、稀にしか使われない助詞は、AIはほとんど選択しない。
4語のフレーズである。[ ]で表しているのが、実際に使われていた助詞。その次の ( )の中に、AIが推定した助詞と、そのスコアが示している。上位3位までが記載している。結構外しているが、言葉として悪いとまでは言えない。
外国人が日本語を話すとき、違和感のある助詞を使うことが結構あり、それが外国人らしいわけだが、そう言う違和感が少ない方がいい。
まあ、このシステムも使えるのではないかと思っている。100万フレーズで学習させたが、データは、1000万以上あるので、それを使えば、もう少し改善するかもしれないが、何しろ学習時間がかかる。
No.10 ソ連 [ の ] (は:0.3630, が:0.1074, と:0.0657)イスラエル の No.11 部門 [ は ] (は:0.4477, も:0.0971, が:0.0948)これ に No.12 伊能 [ の ] (の:0.9223, が:0.0109, と:0.0103)収益 は No.13 旭天鵬 [ において ] (の:0.5412, が:0.1425, は:0.1016)断髪式 で No.14 配置 [ は ] (は:0.2043, の:0.1557, が:0.0794)M16 と No.15 全国野球振興会 [ を ] (を:0.7053, で:0.0437, が:0.0365)務め て No.16 系統 [ が ] (の:0.5002, は:0.1054, と:0.0645)ナビ の No.17 上 [ で ] (の:0.2693, で:0.1684, や:0.0647)電波 の No.18 1954年 [ に ] (に:0.3260, は:0.1242, の:0.0659)パリ国立高等音楽院 に No.19 右派 [ の ] (の:0.8765, や:0.1142, による:0.0180)政治家 など No.20 冬期 [ と ] (と:0.4136, は:0.1240, に:0.0923)なる が No.21 これら [ の ] (の:0.9499, は:0.0109, という:0.0054)培養皮膚 は No.22 標準 [ の ] (の:0.7044, は:0.0623, で:0.0341)圧縮比 が No.23 仁王 [ は ] (の:0.2422, は:0.2047, が:0.0913)運慶 の No.24 愛知県がんセンター [ の ] (の:0.7821, を:0.1101, が:0.0507)研究所 に No.25 ジェーン [ は ] (の:0.5065, と:0.1337, は:0.1181)アルティメッツ の No.26 偽名 [ として ] (を:0.8573, で:0.0346, も:0.0249)使っ て No.27 旅客 [ は ] (の:0.2721, は:0.2641, が:0.0778)大都市近郊区間 を No.28 幕府 [ は ] (の:0.1775, は:0.1584, が:0.1229)金 の No.29 恩師 [ の ] (の:0.8917, を:0.0346, が:0.0148)薦め で No.30 男女共同参画社会基本法 [ の ] (の:0.9504, は:0.0108, による:0.0105)規定 による データスキップ = 信用格付業者::は::証券取引等監視委員会::が No.31 139 [ の ] (は:0.3732, の:0.1103, で:0.0970)アメリカ人 の No.32 段ボール箱 [ の ] (の:0.8884, や:0.0135, を:0.0119)応用 で No.33 高 [ で ] (の:0.8250, で:0.0346, は:0.0272)火入れ が No.34 山下敬吾 [ に ] (の:0.5780, と:0.0956, は:0.0678)1敗 の No.35 大半 [ は ] (の:0.5944, は:0.1356, に:0.0576)ミヤコーバス が No.36 アリーナ [ は ] (の:0.3456, は:0.1212, と:0.0864)パフォーミング・アーツ・センター が No.37 料金 [ は ] (は:0.3200, が:0.1131, の:0.1130)30万円 と No.38 龍造寺隆信 [ の ] (の:0.9836, による:0.0049, も:0.0040)死後 は No.39 違法 [ の ] (の:0.6740, を:0.0612, が:0.0483)経営 に No.40 観光道路 [ の ] (の:0.8684, という:0.0395, や:0.0193)性格 も No.41 ala [ が ] (は:0.2413, の:0.1734, が:0.1581)最大 の No.42 ストレイト [ を ] (は:0.6187, の:0.0653, を:0.0452)標的艦 と No.43 夫 [ の ] (は:0.4473, が:0.1373, と:0.0572)ロバート・ロペス と共に No.44 恩師 [ の ] (の:0.8946, を:0.0244, という:0.0132)薦め も No.45 反射 [ の ] (の:0.2507, は:0.2121, を:0.1552)前部 に No.46 肉 [ と ] (が:0.3772, を:0.1449, は:0.1141)驚く ほど No.47 1985年 [ の ] (に:0.3914, は:0.1182, の:0.0777)ベストセラー と No.48 持つ [ を ] (を:0.6830, の:0.2856, が:0.0529)筆頭 として
ディープラーニングによる日本語の助詞の選択(1)
ディープラーニングで、名詞と名詞(ないしは動詞)をつなぐ助詞を選択させる試みの中間報告となる。数量的な結果はある程度出たので、メモがわりに書いておこうということである。
すでに示してある、名詞+助詞1+名詞/動詞+助詞2というフレーズのうち、助詞1以外の語から、助詞1を選択するというのが問題である。日本語ウィキペディアから1200万個くらいのこの4語のデータを作ったのだが、このうちの100万語を使って、自己符号器型のディープラーニングニューラルネットを学習させた。
ネットワークのトポロジーは、 563 500 400 300 156 となっている。左から入力ユニット(名詞二つのword2vecベクトル、200x2プラス、選択された助詞2、163個の広い出された助詞のうち、使われたものだけが1になっている。これらが入力データ)で、一番右が出力ユニット数(拾われた助詞1の総数163個のうち、実際に使われていたものだがけが1になっているベクトル)
テストはまだ行っていないのだが、データに対して、どれほどの答えを出しているのかを調べてみた。
結果は、10万個のデータに対して、53.6%の正解を示していた。正解は、選択肢の中で、最大出力が解答と同じである場合である。
じっさい、これには正しい答えというのは、あるようでない。「の」が「は」に変わっても大して意味が変わらないこともあるだろう。他の三つの語が同じでも、助詞はいろいろに変わりうるからだ。
政界のユニットが出力している値のヒストグラムは次の図のようになる。横軸が回答ユニットの出力値の幅で、縦軸がその範囲にある頻度である。
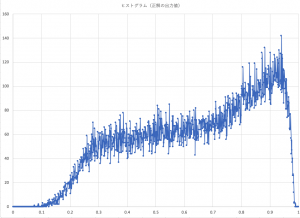
結果をパラパラ見る限り、使えそうな気はしている。教師データを100万個から500万個くらいにあげれば、もっと言いあてるようになると思う。1000万個まで行きたいが、とてつもなく時間がかかってしまう(ただ、この間、ディープラーニングのアルゴリズムやクラス構成、プログラム自体を改良していたのは、教師データを引き上げても、かかる時間以外の、メモリーなどで対応できるようにするためだったのだが)
まあ、まあ、こんなもんだなと言う感じである。実際、どのような文脈で、どのような助詞が選ばれるかについてテストした結果は(まだテストしてないが)、次の記事にする。
ディープラーニングのプログラムを組み直す(2)
相当基本的なところから組み直した。ごちゃごちゃしたプログラムをだいぶ整理した。直しはバグのもとであり、結局、MNISTの手書き文字の認識まで戻ってテストせざるを得なくなった。
ディープラーニングのエンジンである、バックプロパゲーションのところだけは、流石にいじらなかった(笑)ここをいじり始めたら収拾がつかなくなる。
以前は、学習とテストを同じ関数でやっていたが、きちんと切り分けた。CUIからGUIにインターフェイスをレベルアップさせた。
かなり拡張性も出てきたと思う。MNISTの正解率も以前のものと同じものに戻った。オブジェクトというか、クラスをかなり整理したので見やすいプログラムになったと思う。
これで、最適助詞選択プロジェクトに入る。
一文章の要約システム(6) : データフォーマットの変更
これまでの話では、「名詞」+「助詞」+「名詞/動詞」の3語のパターンで、深層学習のデータを作ると書いたが、実際できたデータを見ると、前後の語から間の助詞を判断するのは、自分で見ても難しい。そこで、もう一つ助詞をとって、
「名詞」+「助詞」+「名詞/動詞」+「助詞」
のパターンで、はじめの助詞を推定するという構造に変えた。これで日本語wikipediaデータをパースすると、前よりもデータ数は減ったが、それでも、17,588,062対を得ることができた。これで、深層学習のデータを作成しよう。
データ(一部)は次のような感じである。
体:は:羽衣:の もの:が:付い:て 輸送:において:採算:を 千年:から:エネルギー:を 延長:を:図っ:て 路線:を:中心:に 7日間:しか:目:を ジラーチ:は:ロシア語:で ハイダル・アリー:は:戦争:の その後:も:戦争:は イギリス:は:マンガロール:に 1784年:に:第二次マイソール戦争:は マンガロール:で:休戦:と これ:は:インドの歴史:で インド:の:民族:にとって イギリス:に:腰:を し:て:休戦:を ウォーレン・ヘースティングス:は:これ:を 国王:と:議会:に 市内:の:殆ど:の 地域:で:最寄駅:まで 線:を:皮切り:に 通常:の:プレイ:で 路線:の:開設:に 210:は:バス路線:の 空白域:を:ピンポイント:で 2004年:から:2008年:にかけて 1780年:は:武装中立同盟:に ため:に:増発:を キャンペーン:の:一環:として ネーデルラント連邦共和国:に対し:先手:を 深夜バス:の:運行:も 武装中立同盟:は:ヨーロッパ:の 6月19日:から:7月17日:まで 間:に:ニンテンドーWi-Fiコネクション:で 結果:は:ヨーロッパ:で 赤字:が:続い:て 7月1日:から:7月31日:まで イギリス:は:ネーデルラント:が 扇動:と:オランダ政府:の イギリス:の:攻撃:を ホウエン地方:の:トクサネシティ:の フレーズ:を:口:に これら:の:こと:から セレビィ:と:ウバメ:の 独立戦争:の:最初:の これ:を:基:に
一文章の要約システム(5) :深層学習による最適助詞の推定
色々考えてきたが、ここに及んで、深層学習に頼ることにした。アイデアをより詳しく語ると、word2vecと深層学習をつなげてみようということだ。
まず、日本語ウィキペディアから拾ってきた、名詞+助詞+(名詞・動詞)のデータは、4000万個になった。両脇の名詞、あるいは動詞から、それらをつなぐ間の助詞をどう推定するのか、データを眺めていてもさっぱりラチがあかない。前後の名詞と動詞を品詞化して、次のような感じにして、情報を集めたが、これでもパッとしない。
巡洋艦(名詞,一般,*,*):が(助詞,格助詞,一般):支援(名詞,サ変接続,*,*) 愛知県名古屋市西区(名詞,固有名詞,地域,一般):の(助詞,連体化,*):上小田井駅(名詞,固有名詞,地域,一般) 古代ローマ(名詞,固有名詞,一般,*):は(助詞,係助詞,*):ギリシア(名詞,固有名詞,地域,国) インクジェットプリンター(名詞,固有名詞,一般,*):に(助詞,格助詞,一般):対象(名詞,一般,*,*) 祭神(名詞,一般,*,*):は(助詞,係助詞,*):博多区(名詞,固有名詞,地域,一般) 処理(名詞,サ変接続,*,*):が(助詞,格助詞,一般):いくつ(名詞,代名詞,一般,*) キャピタルワン(名詞,固有名詞,一般,*):を(助詞,格助詞,一般):買収(名詞,サ変接続,*,*) 政権(名詞,一般,*,*):を(助詞,格助詞,一般):とる(動詞,自立,*,*) 婚姻(名詞,サ変接続,*,*):の(助詞,連体化,*):20%(名詞,固有名詞,一般,*) 10節(名詞,固有名詞,一般,*):に(助詞,格助詞,一般):定め(動詞,自立,*,*) サッカー(名詞,一般,*,*):は(助詞,係助詞,*):0(名詞,数,*,*) ヤン・ヴァーツラフ・ヴォジーシェク(名詞,固有名詞,人名,一般):の(助詞,連体化,*):作曲(名詞,サ変接続,*,*) 男子シングルス(名詞,固有名詞,一般,*):で(助詞,格助詞,一般):最初(名詞,一般,*,*) たよっ(動詞,自立):て(助詞,接続助詞,*):霧(名詞,一般,*,*) 人物(名詞,一般,*,*):の(助詞,連体化,*):風景(名詞,一般,*,*) 板垣退助(名詞,固有名詞,人名,一般):が(助詞,格助詞,一般):第2次(名詞,固有名詞,一般,*) 前線(名詞,一般,*,*):に(助詞,格助詞,一般):なり(動詞,自立,*,*) 存廃(名詞,一般,*,*):の(助詞,連体化,*):判断(名詞,サ変接続,*,*) 連城(名詞,固有名詞,人名,姓):の(助詞,連体化,*):憧れ(動詞,自立,*,*) 型(名詞,接尾,一般,*):の(助詞,連体化,*):吸入(名詞,サ変接続,*,*) 地区(名詞,一般,*,*):も(助詞,係助詞,*):発生(名詞,サ変接続,*,*) 王座(名詞,一般,*,*):を(助詞,格助詞,一般):アグスティン(名詞,固有名詞,人名,一般) ELMS(名詞,固有名詞,組織,*):の(助詞,連体化,*):LMP(名詞,一般,*,*) たち(名詞,接尾,一般,*):は(助詞,係助詞,*):11月23日(名詞,固有名詞,一般,*) 舞台(名詞,一般,*,*):は(助詞,係助詞,*):ポルトガル(名詞,固有名詞,地域,国) 1944年(名詞,固有名詞,一般,*):に(助詞,格助詞,一般):主税局(名詞,固有名詞,組織,*) 現象(名詞,一般,*,*):について(助詞,格助詞,連語):幾分(名詞,一般,*,*) 湾(名詞,接尾,一般,*):の(助詞,連体化,*):北(名詞,一般,*,*) 代(名詞,接尾,一般,*):に(助詞,格助詞,一般):結婚(名詞,サ変接続,*,*) 上番(名詞,一般,*,*):や(助詞,並立助詞,*):平安時代(名詞,固有名詞,一般,*) 3月(名詞,固有名詞,一般,*):は(助詞,係助詞,*):永田鉄山(名詞,固有名詞,人名,一般) シュテティーン(名詞,一般,*,*):で(助詞,格助詞,一般):商業(名詞,一般,*,*) ホルティ(名詞,一般,*,*):は(助詞,係助詞,*):反共主義者(名詞,固有名詞,一般,*) 冏(名詞,一般,*,*):を(助詞,格助詞,一般):討つ(動詞,自立,*,*) プラットフォーム(名詞,一般,*,*):の(助詞,連体化,*):合計(名詞,サ変接続,*,*) ショパン(名詞,固有名詞,人名,姓):によって(助詞,格助詞,連語):フルート(名詞,一般,*,*)
品詞を使うことも考えたが、品詞情報はとても弱い。助詞の選択は、品詞で機械的にも止まるものではなく、前後に使われている名詞や動詞の意味に連結しているのだ。
そこで、深層学習を利用しようということになった。前後の言葉を入れると、最適助詞を選び出すようなニューラルネットワークを構築すれば良い。深層学習のjavaプログラムはすでに作ってある。自己符号化型のものだが。
ただ、言葉膨大にある。入力ユニット数を数万に増やすわけには行かない。そこで、言葉をword2vecを用いて、200次元ベクトルで表し、前後の言葉で、合計400次元にすれば、難なく、深層学習で扱える。出力は、助詞のいずれか一つが選択されるように、助詞の数だけのユニットだから、それは、限られた数で良い。せいぜい数十個だろう。
4000万個のうち、3000万個くらいを学習させて、残りの1000万個でテストすれば良い。早速データを作ろう。
自然言語とコンピュータ言語
自然言語(日本語とか英語など)とコンピュータ言語(JAVAとかC++など)は、どう違うんだろうと考えることはままある。
が、ふと、同じようにできるのでないかと思った。
例えば「私は人間である」というのは自然言語だ。これをJAVA的に表すと
String watashi = "人間";
しかし、これが変なのは、「私は学生です」もありえるが、一旦、人間ですを入れると学生ですが入れられなくなるのだ。
だったら、watashiをクラスにすればいい。
class Watashi {
List<String> attributes = new ArrayList<>();
}
こういうクラスを作っておいて、
Watashi watashi = new Watashi()
とインスタンス化すれば、
watashi.attributes.add("人間");
watashi.attributes.add("学生");
などと、いくらでも私という存在の属性を加えていくことができる。逆にこのインスタンスがあれば、
String reply(String question){
switch(question){
case "あなたは何ですか":
return "私は"+attributes.get(0)+"です";
case "あなたは学生ですか":
if(attributes.contain("学生")){
return "はいそうです";
}else{
return "いえ、私は学生ではありません";
}
}
return "わかりません";
}
などと、質問に対して答えることができる。これで、do(する)、playなども関数としてクラスに組み込むことができる。