RaspberryPi上で、Juliusを使って音声認識させ、open_jtalkで音声合成し、音声を出力するまでの一連の手続きの覚書である。
まず、juliusについては、ダウンロードしてコンパイルするだけで良い。ただし、 --enable-words-intオプションをつけたほうが良いかと思うが、現状していない。いずれ、制約が大きいと感じたら、こんんパイルし直せば良い。-mictypeも指定していなかったと思う。記憶は定かではない。
Juliusには、音響モデルと言語モデルが必要なのだが、このキットがダウンロードできる。最終的には、用途にあったモデルを作成する必要があるが、そう難しくはない。『音声認識システム第2版』などを参考にするとよくわかる。
キットを使う場合にはいくつか注意が必要だ。まず、前提として、macで同じことをやろうとすると、juliusをモジュールモードにした時にコマンドが正常に働かない。juiiusをjavaからコントロールする場合、ネットワークソケットを経由するのが最も便利だ。他に、ライブラリのlibjuliusだけを用いて、それをjavaのjnaを使って、javaから呼び出す方法も考えられるが、文字コード変換機能を自前で用意しなければならなかったり(そう難しくないようだ)、いろいろなコマンドを制御しなければならないので面倒になる。
Macでコマンドが働かないと言うのは、音声を喋らせているときは認識をPAUSEしなければ、喋っている音声を認識してしまうので、エコー化してしまう。それが終わったらRESUMEコマンドで再度認識させるようにしなければならないのだが、MACの場合、一旦PUASEしてしまうと再度、RESUMEしても、なぜだか認識するようにならないのだ。いろいろ探ったがダメだった。諦めた。本来、RaspberryPIで動けば良いので、macの問題は無視することにした。RaspberryPIの場合は、PAUSEとRESUMEコマンドは正常に機能する。
次に、文字認識キットの使用方法についてだ。当面使うのがいいと思うが、juliusのサイトには3種類置かれている。ディクテーションキットと話し言葉モデルキットが使われるべきだと思う。まず、後者は、dnn、すなわち深層ニューラルネットが使われているものであり、前者は、深層ニューラルネットとGMMの二つがある。基本、DMMモデルは認識が遅い。時間がかかる。
前者で、GMMを使うときのコマンドラインは、ディクテーションキットがあるディレクトリで、
julius -C main.jconf -C am-gmm.jconf
とやる。モジュールモードにするときは、
julius -C main.jconf -C am-gmm.jconf -module
とすれば良い。ディクテーションキットのdnnを使うときは、
julius -C main.jconf -C am-dnn.jconf -dnnconf julius.dnnconf
と-dnnconfオプションが必要となる。モジュールにする場合は、先と同様に-moduleを付け加えれば良い。
話し言葉キットの場合は、そのディレクトリで、
julius -C main.jconf -dnnconf main.dnnconf
とする。これについては、フォルダに、run.batがあるので、それを確認すれば良い。
次に、open_jtalkを使った音声合成である。
/usr/bin/open_jtalk -m /usr/share/hts-voice/Mei/mei_normal.htsvoice -x /var/lib/mecab/dic/open-jtalk/naist-jdic
の後に-owで出力のwavファイル名を指定して、その後にテキストファイルを直接指定する。上記は女性の声になる。女性の声を入れて置かなければならない。
できたwavファイルについては、aplayで発声させるのであるが、先の記事にも書いたように、
aplay -D plughw:2,0 test.wav
でオプションをつけないと音はならない。
デバイス番号については、
cat /proc/asound/cards
で調べる。私の場合は、
0 [Device ]: USB-Audio - USB PnP Audio Device
C-Media Electronics Inc. USB PnP Audio Device at usb-3f980000.usb-1.5, full spe
1 [ALSA ]: bcm2835 - bcm2835 ALSA
bcm2835 ALSA
2 [DAC ]: USB-Audio - USB Audio DAC
Burr-Brown from TI USB Audio DAC at usb-3f980000.usb-1.3, full speed
で、DACは2番なのだ。
ボリュームについては、
alsamixer -c 2
で、調整する。10Wx2では、相当小さくしないと、うるさい。
カテゴリー: 自然言語処理
TwitterStreamingによるツイートイベントの取得
Twitter Botの前の記事の仕様では、bot側から@aigeininへのツイートを取得しなければならなかった。そのために、お題が投稿されたタイミングがわからないから、15秒おきにツイートを取りに行っていた。これが面倒だった。
そこで、TwitterStreamingAPIを使って、投稿のイベントを取得することにした。
twitter4jのサンプルにちょっとだけ手を加えたものは次のようになる
public static void main(String[] args) throws TwitterException {
TwitterStream twitterStream = new TwitterStreamFactory().getInstance();
twitterStream.setOAuthConsumer(consumerKey, consumerSecret);
twitterStream.setOAuthAccessToken(new AccessToken(accessToken, accessTokenSecret));
AiGeininBot2 aig = new AiGeininBot2();
StatusListener listener = new StatusListener() {
// フィルターをかけたツイートが取れると、このリスナーが呼び出される
@Override
public void onStatus(Status status) {
// ツイート内容がStatusで与えられる
System.out.println("@" + status.getUser().getScreenName() + " - " + status.getText());
// statusを与えて、次のメソッドで処理する
aig.execNazokake(status);
}
@Override
public void onDeletionNotice(StatusDeletionNotice statusDeletionNotice) {
System.out.println("Got a status deletion notice id:" + statusDeletionNotice.getStatusId());
}
@Override
public void onTrackLimitationNotice(int numberOfLimitedStatuses) {
System.out.println("Got track limitation notice:" + numberOfLimitedStatuses);
}
@Override
public void onScrubGeo(long userId, long upToStatusId) {
System.out.println("Got scrub_geo event userId:" + userId + " upToStatusId:" + upToStatusId);
}
@Override
public void onStallWarning(StallWarning warning) {
System.out.println("Got stall warning:" + warning);
}
@Override
public void onException(Exception ex) {
}
};
twitterStream.addListener(listener);
// ここで @aigeinin 向けたツイート、リプライだけを取得するためのフィルターを作る
final String[] TRACK = { "@aigeinin" };
FilterQuery filter = new FilterQuery();
filter.track(TRACK);
// ここでフィルターを組み込む
twitterStream.filter(filter);
}
word2vecでロボットに言葉の演算をやらせた
この間、ずっとはまっていたのは、word2vecを使い、wikipediaに登場する単語を演算可能にすることだった。そこに、ボケの匂いを感じたのだ。word2vecは、ニューラルネットを使って、言葉を数量ベクトル化する手法だ。すると、言葉の演算がベクトル演算に変化できて、面白い結果が出てくる。
http://www.blog.umentu.work/ubuntu-word2vec%E3%81%A7%E6%97%A5%E6%9C%AC%E8%AA%9E%E7%89%88wikipedia%E3%82%92%E8%87%AA%E7%84%B6%E8%A8%80%E8%AA%9E%E5%87%A6%E7%90%86%E3%81%97%E3%81%A6%E3%81%BF%E3%81%9F/
と
http://qiita.com/tsuruchan/items/7d3af5c5e9182230db4e
を参考にした。
wikipediaデータをmecabで分かち書きした膨大な単語について、演算が可能になった。たとえば、
ギター+キーボード
という演算をやらせると「セッション」になるとか。面白い。ネタになる。
隠れユニット200個で、学習結果のウェイトマトリクスデータが、900メガバイトを超える。
このデータは、ロボットNAOのストレージには入らない。そこで、NAOのUSBポートからデータをロードしようとしたら、当然のことなのだが、mallocで確保しようとしたヒープのメモリが、確保できない。仕方がないので、このデータを処理するライブラリを、パソコン上において、naoqiのリモートライブラリとすることで解決した。
人工知能など、およそ、その機能をロボットに全部組み込む事は不可能なので、PC上のリモートライブラリにするのはある意味自然なのだが、ロボットを立ち上げ、さらにリモートでライブラリを立ち上げるのは面倒だ。
しかも、言葉の聞き取りは、これも実に面倒なのだが、qichatを使って、トリがを与え、ロボットに喋りかけた言葉をwav音声データにして、パソコン上のサーバーに送って、それをさらにrawデータに変換したりして、Google cloud APIの音声認識システムに送って、テキスト化し、それをまたパソコン上で、形態素分析して、必要なデータを取り出し、またロボットのqichatのスクリプトの中にイベントとして取り組むと言う、質面倒臭いことをやる。それで、10秒くらい使ってしまうのが痛い。
しかし、まあ、これで、結構な人工知能をロボットに組み込んだことになる。
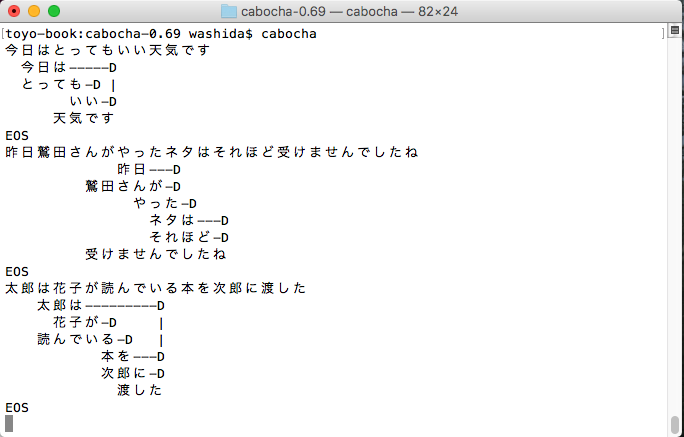
形態素解析と係り受け解析
どちらもGoogle Cloud APIでできるのだが、もうひとつ、いいものだという実感がないので、日本で開発されたMecabとCabochをインストールしてみた。以前、kuromojiも動かしたことがあるので(このサイトにも掲載してある)その辺りはある程度わかっているが、どれをどのように使うのかという迷いはある。kuromojiで形態素解析をして、その要素を使うだけで良いような気もするが、係り受け解析は必要か。
Google Cloud APIのいいところは、rootの単語を拾い出すことのような気がする。
しばらく迷う必要がある。ただ、あと2週間以内に、ロボットにちょっとしたことをさせたいと思っている。
以下は、CaboChaでの出力の画像である。