この間、ずっとはまっていたのは、word2vecを使い、wikipediaに登場する単語を演算可能にすることだった。そこに、ボケの匂いを感じたのだ。word2vecは、ニューラルネットを使って、言葉を数量ベクトル化する手法だ。すると、言葉の演算がベクトル演算に変化できて、面白い結果が出てくる。
http://www.blog.umentu.work/ubuntu-word2vec%E3%81%A7%E6%97%A5%E6%9C%AC%E8%AA%9E%E7%89%88wikipedia%E3%82%92%E8%87%AA%E7%84%B6%E8%A8%80%E8%AA%9E%E5%87%A6%E7%90%86%E3%81%97%E3%81%A6%E3%81%BF%E3%81%9F/
と
http://qiita.com/tsuruchan/items/7d3af5c5e9182230db4e
を参考にした。
wikipediaデータをmecabで分かち書きした膨大な単語について、演算が可能になった。たとえば、
ギター+キーボード
という演算をやらせると「セッション」になるとか。面白い。ネタになる。
隠れユニット200個で、学習結果のウェイトマトリクスデータが、900メガバイトを超える。
このデータは、ロボットNAOのストレージには入らない。そこで、NAOのUSBポートからデータをロードしようとしたら、当然のことなのだが、mallocで確保しようとしたヒープのメモリが、確保できない。仕方がないので、このデータを処理するライブラリを、パソコン上において、naoqiのリモートライブラリとすることで解決した。
人工知能など、およそ、その機能をロボットに全部組み込む事は不可能なので、PC上のリモートライブラリにするのはある意味自然なのだが、ロボットを立ち上げ、さらにリモートでライブラリを立ち上げるのは面倒だ。
しかも、言葉の聞き取りは、これも実に面倒なのだが、qichatを使って、トリがを与え、ロボットに喋りかけた言葉をwav音声データにして、パソコン上のサーバーに送って、それをさらにrawデータに変換したりして、Google cloud APIの音声認識システムに送って、テキスト化し、それをまたパソコン上で、形態素分析して、必要なデータを取り出し、またロボットのqichatのスクリプトの中にイベントとして取り組むと言う、質面倒臭いことをやる。それで、10秒くらい使ってしまうのが痛い。
しかし、まあ、これで、結構な人工知能をロボットに組み込んだことになる。
カテゴリー: Google Cloud Platform
gRpcについて
Google cloud platformの元になっているが、grpcというシステムなのだが、これがよくわからないので、理解しようと思って、
http://www.grpc.io/docs/quickstart/java.html
ここにおいてあるサンプルを動かそうと思ったら、つまずいたので、対処した方法を以下に書いておく。
(1)そこに書いてある以下を実行する。
$ # Clone the repository at the latest release to get the example code:
$ git clone -b v1.0.3 https://github.com/grpc/grpc-java
$ # Navigate to the Java examples:
$ cd grpc-java/examplesこれは問題なくできるだろう。
(2)次の、
$ ./gradlew installDistを実行すると、FAILURE: Build failed with an exception.がでて失敗する。
そこで、
https://github.com/grpc/grpc-java/issues/581
ここの下の方に書いてある対処を実行する。
すなわち、元のフォルダにある、
run-test-client.sh
run-test-server.sh
のそれぞれの最後に、
-PskipCodegen
を一行入れて、再度
$ ./gradlew installDistを実行すると、うまくいくはずである。
$ ./build/install/examples/bin/hello-world-server
$ ./build/install/examples/bin/hello-world-clientを実行する。
JavaでGoogle Cloud API ストリーミング
ロボットのAI処理のサーバーをJAVAで作っているので、Pythonでやってきた、Google Clouf APIのストリーミング言語処理をJavaで動かす必要があった。まえから、Javaバージョンを試してみたかったのだが、解説を読んでもすぐにわからないところがあったので、pythonに流れた。ちょっと本気でやってみた。
一見わかりにくいと思ったのは、逆にpythonよりも動かすのは簡単だったからだ。記録のために書いておこう。何しろ老人だから、記録しないとすぐに忘れる。このサイトは、私の忘却防止のためにおいているようなものだから。
基本的に、
https://github.com/GoogleCloudPlatform/java-docs-samples/tree/master/speech/grpc
に記載されていることを実行するだけなのだが、Pythonより、そっけなく書かれている。
(1)google cloud platformの認証関係の手続きは、pythonのところで書いたことをやっておけば、全部スキップできるので、あえてここでは書く必要がないと思う。一つだけ書いておくと(自分のために)、もし、認証に失敗したら、環境変数に認証データファイルを定義し直す必要があるのかもしれない。環境変数が何気に消えているときがあるので。たとえば、次のように。
export GOOGLE_APPLICATION_CREDENTIALS=/Users/path/to/プロジェクト名のついた認証ファイル.json
認証ファイルはGoogle Cloud Platformの認証手続きを行えばもらえる。
(2)Mavenをインストールする。これは、そのサイトにアクセスして言われた通りにやれば良いと思う。
(3)ビルドだが、githubに慣れていない、と言うかほとんど知らないので、上記のアドレスを指定して、gitを実行してもうまくいかなかった。よくわかっている方がいたら、教えて欲しいが、自分でも、もう少し勉強したいと思う。ただ、パスを遡って、もう少し上で、gitを実行したらうまくいった。まず、
git clone https://github.com/GoogleCloudPlatform/java-docs-samples/
を実行する。すると、そこにjava-docs-samples/のフォルダができて、その下にspeech関係のサブフォルダ以下も作成されているはずだ。
(4)java-docs-samples/speech/grpcに降りて、そこにpom.xmlがあることを一応確認しよう。そして、解説によれば、mvn projectでも良いと書いてあったが、そっちではうまくいかなかったので、もう一つの、
$ mvn compile $ mvn assembly:single
の二つのコマンドを順に実行する。
(5)次のコマンドで実行させる。
bin/speech-sample-streaming.sh --host=speech.googleapis.com --port=443 --sampling=16000
ただこれだと、マイクに向かって喋っても、ローマ字か英語で帰ってくるだけである。Ctl_Cで中止する。
(5)srcのフォルダを一番下まで辿っていくと、
StreamingRecognizeClient.java
というソースがあるので、それをエディタで開いて、197行目からの、
RecognitionConfig.newBuilder()
.setEncoding(AudioEncoding.LINEAR16)
.setSampleRate(samplingRate)
.setLanguageCode("ja-JP") // ←※
.build();
上に”←※”で指示した一行を加える。これは、
https://cloud.google.com/speech/reference/rest/v1beta1/RecognitionConfig
に開設されているRecognitionConfigのオプションだ。
(6)以下のコマンドでビルドする。
$ mvn clean
$ mvn clean $ mvn compile $ mvn assembly:single
(7)再度実行する。
bin/speech-sample-streaming.sh --host=speech.googleapis.com --port=443 --sampling=16000
マイクに向かって喋ると、日本語のテキストになってコンソールに表示されるはずです。表示のされ方は、pythonの場合とほぼ同じ、中間状況が表示される。
人の問いかけにWikipediaを答えさせた
今日は1日、時間が取れたので、午後ずっと、ロボットのプログラミングをやっていた。なんとか、ロボットにお題を問いかけて、そのお題をWikipediaにアクセスして調べさせて、主要な答えを返すというところまでやらせたが、まだまだ不安定で、実用性が低い。他の言葉は、ランダムにボケさせただけ。
不安定さについては、また別に書こうと思う。
sallybotというシステム名にした
この間のシステムを、現在のマイロボットの名前と同じ、sallybotと呼ぶことにした。
python からmysqlをつかうためのMySQLdbのインストール
virtualenvで、Google cloud関係のシステムを動かしているので、対話ボット関係のためにインストールしたモジュールが読み込めなくなっていたので、その環境でもう一度インストールしようと思った。だいたいできたのに、MySQLdbだけが、忘れていて、改めて以下のコマンドでインストールしたことをここに記録しておく。
(env) toyo-book:sally washida$ pip install MySQL-python
Google Cloud APIのストリーミングを継続して使う
Google Cloud APIのストリーミング音声認識を、ロボットとの継続した対話に使おうとすると、60秒の制限があって、それ以上使えずに、例外が発生してアボートしてしまう。これでは使えない。
そこで、gracefull(優美)に一つの会話を終了させながら、次の会話に入っていくということがどうしても必要になる。その基本的なやり方を以下に記しておく。
(1)ロボットからの音声データのストリーミング入力は、それとして生かしておくという戦略。
(2)Google Cloudからは、送られたーデータの解析結果が中間的に、最終的にの二つのバージョンで送られて来るが、最終バージョンが送られて来たら、それを一旦出力(エコーロボットとしてロボットに喋らせる、あるいは、人間入力の言葉を解析して応答を用意したりして)
(3)これで例外を発生させずに終わるが、これだと一回の聞き取りしかできなくなってしまう。そこで、
requests = request_stream(buffered_audio_data, RATE)
のスレッドの作成から、再度はじめ直す必要がある。そこでここからを関数化して、先の終了後に、再帰的にこの関数を呼び出すようにすればいい。すると、また60秒制限の新しいスレッドが立ち上がる。無限続けるのは良くないので、いったい何度ロボットやり取りするかを事前に与えておいて、その回数の会話をしたら全てを終了させるようにすれば良い。
(4)一つ問題は、(2)で、会話が入れば、一つのスレッドはグレースフルに終わるが、無言の時間が続くと終わるタイミングを逃して例外を発生させてしまう。そこで、60秒以内の一定時間無言が続くと、一旦gracefullに終わらせる。
そこで、次のようなタイマーイベントを、先に分離した関数部分の中に置いておく、
###############
def stopAPI():
print "ループを止めます"
recognize_stream.cancel()
#ここまでが関数、以下でタイマーでこのハンドラーを呼び出す
t=threading.Timer(MAX_SILENT_LENGTH,stopAPI)
t.start()
###############
関数の中にstopAPIという関数を定義して、MAX_SILENT_LENGTHの秒数が経過すると、
recognize_stream.cancel()
というイベントを発生させる。すると、CANCELLという例外が発生して、綺麗に終わるように例外処理手続きが組み込まれているのでうまくいく。そしてこの例外処理が終わった後、さいど、先に作成した関数、request_streamから始める関数をスタートさせれば良い。
これで、指定回数の会話が終わるまで、継続的にGoogle Cloud APIでストリーミング処理を続けることができる。
これで、人工無脳の会話ボットと、ロボットNAO、そしてGoogle Cloud APIの三つをつなぐ準備が80%ほど、整った。
人工無脳の会話ボットとGoogle Cloud APIの接合
「pythonプログラミングパーフェクトマスター」のマルコフ連鎖の応答部分を、WikiPediaからの情報に基づいたものにするという、ほぼ、目的どうりの人工無脳会話ボットができた。
人工無脳は、ほぼお笑いのボケの一種となる。つっこめるのだ。
一方、お題についてのWikipedia情報は、人工知能的なもので、そのギャップが笑いになる。
これをGoogle Cloud APIのスピーチシステムに接合すれば目的のものが出来上がる。
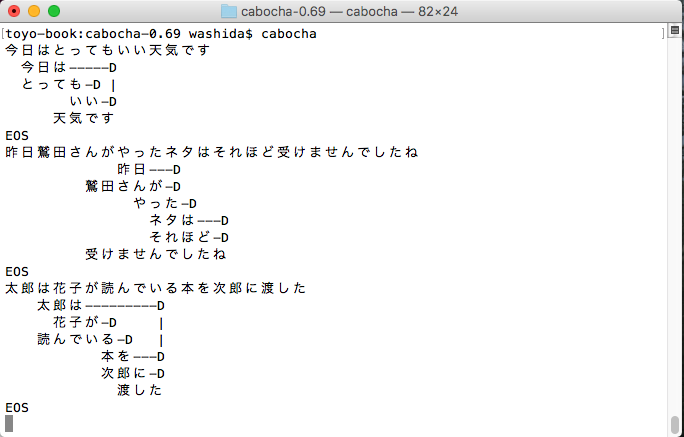
形態素解析と係り受け解析
どちらもGoogle Cloud APIでできるのだが、もうひとつ、いいものだという実感がないので、日本で開発されたMecabとCabochをインストールしてみた。以前、kuromojiも動かしたことがあるので(このサイトにも掲載してある)その辺りはある程度わかっているが、どれをどのように使うのかという迷いはある。kuromojiで形態素解析をして、その要素を使うだけで良いような気もするが、係り受け解析は必要か。
Google Cloud APIのいいところは、rootの単語を拾い出すことのような気がする。
しばらく迷う必要がある。ただ、あと2週間以内に、ロボットにちょっとしたことをさせたいと思っている。
以下は、CaboChaでの出力の画像である。
自然言語処理のGoogle Cloud APIを使ってみた
ロボットのキャッチした音声データをGoogle Cloud APIでテキスト化することの見通しがほぼたったので、それを自然言語処理のGoogle Cloud APIで、意味的理解の基礎付けをしようと思った。
https://github.com/GoogleCloudPlatform/python-docs-samples/tree/master/language/api
に記載されている内容をそのままなぞって、実現することができた。Speechの場合と違うことは、
$ pip install -r requirements.txt
を実行する上での内容の違いだけである。
また、unicode文字列のエスケープをデコードする必要があるが、
http://d.hatena.ne.jp/gepuro/20120317/1331991888
にある、pythonプログラムを使用すると簡単になる。
いよいよ、本丸に近づいてきた。