telloには、独自のプログラミングしステはあるが、UDPでコマンドを送った方が、柔軟性がある。音声認識や、画像処理などで。
Javaでシステムができた。
試しに動かした画像はこれだ。
telloには、独自のプログラミングしステはあるが、UDPでコマンドを送った方が、柔軟性がある。音声認識や、画像処理などで。
Javaでシステムができた。
試しに動かした画像はこれだ。
ドローンもある意味、ロボットの一種だが、いま、プログラムでコントロールするドローンに、強い興味を持っている。
先日、おもちゃのドローンを5000円で買って、この間、操縦の練習に部屋の中で飛ばしていた。やりながら、ドローンと人間というのは、なんだか笑える気がしてきた。ただ、コントローラーを持っているだけでは、面白くない。一番いいのは、プログラムで動くようにすることだ。C++とか、Javaて、動かせるのがいい。
簡単に見つかるだろうと思って、あちこち探したが、以外にこれが見つからない。そんなに世の中にないということは、間違いない。
結局、見つかったのはこれだ。
「Ryze Technologyのトイドローン Tello」
一年以上前に発売されたものだがいまだに人気があるそうだ。組み立てキットのようだが、アマゾンから出ているので、12800円と今のより、少し高いが、注文した。
仕組みは簡単だ。いくつかの記事をま 見たが、要は、ドローンと、wifi接続して、ポソコンなどからUDPでコマンドを送れば良いわけだ。動きを制御するコマンドだけではなく、ドローンの状態を得るためのコマンドもある。
こういうことであれば、Javaであろうが、C++であろうが、プログラムはなんで書いても良い。
基本的にKNPの構文解析に依存した形で作る。前は、KNPだけではなく接続詞や助詞などを考慮して二分木の構造を作っていたが、基本、KNPをベースにしその上で、他を顧慮することにする。
KNPは、係り受け解析なので、それをどう使うかである。
KNPは、文節、タグ、そして形態素解析の個々の要素という構造を持っている。文節とタグはそれぞれ独立した係の番号を持っている。ただし、相互に矛盾しているわけではない。その上で基本、文節の係り受けをもとにする。
ある文節mから開始するとしよう。再帰構造を前提にする。mのかかり先がm+1だった場合、リストにm+1を加え、次を調べる。次ではなくて、mの係先がm+kだった場合、それまでの文節リストとかかり先をセットにして保存する。次にm+1を調べる。
このm+1から順に調べて行って、その、最終的なかかり先がm+kよりも大きくなることはあり得る。しかし、最終的なかかり先が二つになることはない、
ということて、まず、mがm+kにかかっている場合。mまでを部分知識として登録する。m+1以降もそれを繰り返して、m+kまでの部分知識が、すべて確定したら、m+kからの分とそれにかかっているすべての部分知識を含めて、一つの部分知識とする。
このアルゴリズムでなんとかなりそうだが。
ただ、どこまで、KNPが、文法構造を正しく捉えているかがポイントだ。
今更感があるが、一番元々の二分木のフォーマットを変えようという気になっている。最近、11時ごろに寝て、一旦4時ごろに目がさめる。若い頃だったらありえなかったが。それから、寝ながら、いろいろ考えると、アイデアが浮かぶ。そのうちまた、6時ごろまで寝てしまう。アイデアは、新鮮に覚えているというパターン。
今朝のアイデアが、二分木の作り方を変えるというもの。結構いいところまで追い詰めたのに、最近煮詰まった感が出てしまった。(リフレッシュするように、アマチュア無線の3級の免許を取ろうなどと考えてしまっていた。これは、9月29日に試験を受けにいく。恥ずかしく、落ちてしまいそうな気もするが。)
なぜ煮詰まったのか。もともとの二分木作りのところは、見直さないといけないと思いつつ、結局どこまで行けて、何がやれるのかを見極めるように先を進んでいったが、最後の詰めで、これでは難しいな、と思ってしまって、先に行かなくなった。それで、今朝のひらめきである。つまり、気になっていた二分木の作り方をかなりドラスティックに変えるべきだということだ。ポイントは次である。
「二分木構造そのものが、部分知識を表現するものでなければならない」
というものである。たとえば、wikipediaの一つの文章を例示する。
「据え置き型の製造機械である産業用ロボットは、それらが動かない限り、ロボットと呼ばれる自動機械であり、人間社会に与える影響も旧来の自動機械と同等と考えられたが、これからの人間社会は移動するロボットからの影響を受けることが想像される」
この文章から、今までのシステムで、部分知識を取り出そうとした時、少しもうまく行かなかった。これが、煮詰まりのきっかけである。今のシステムでどうなるかはさておいて、こうなるべきだという、前向きのところから考えていきたい。
まず、これをknpで構文解析して、係り受けだけ見てみよう。
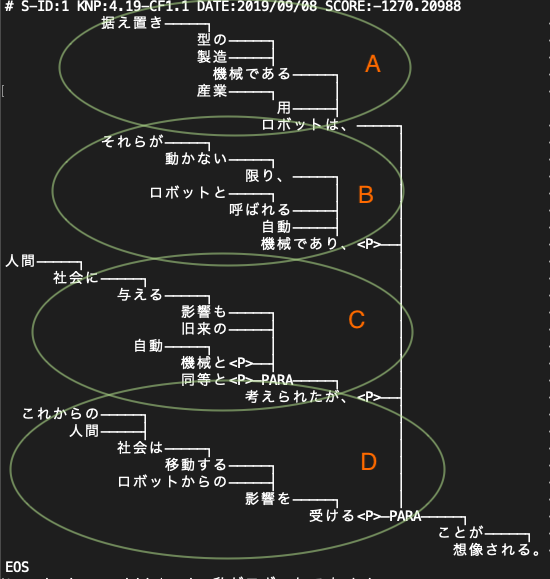
いままで、係り受け解析は、二分木を作る際に使っていたが、そんなに信頼していたわけではない。しかし、これを見る限り、うまく部分知識を表現している。つまり、それぞれのブロックが、一つの部分知識を表している。Aでは、「産業用ロボットというのが、据え置き型の製造機械である」こと、Bでは、「動かない限り、自動機械だ」ということ、「人間社会に与える影響も自動機械に過ぎないと考えられていた」ということ、そして、最後がこの文章の一番の要点である。すなわち「これからの人間社会は、移動するロボットからの影響を受ける」ということである。
部分技を、あるnodeから以下を取り出したときに、部分知識になるように構成したいわけである。
二分木の作り方が混乱していた。首尾一貫した構成を実現する。
ロボットに舞台で喋らせる時、構成した情報について、文章を短くしたい時、要約したい時が頻繁にあったが、ぶち切れのまま喋らせたりしていた。実に不自然だ。そのため、文章の終わり方については、とても気になる。
これまでに示してきた、wikipediaのprolog化した宣言文での文章の終わり方のパターンを調べてみた。まず、全体的な状況を見ると次のグラフのようになる。縦軸は、文章の頻度だ。(ただし、体言止めは、含んでいない:1割以上が体言止めという感じもあるが、文章の正規の終わり方ではないので除外した)
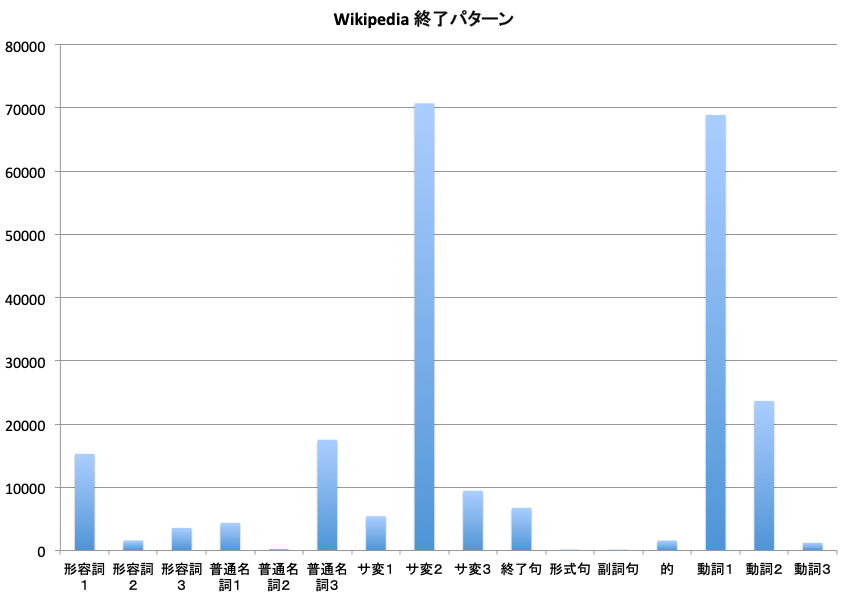
一番多いのは、サ変2というパターンである。例としては次のようなものがある。
実現(S:サ/C:抽象物)さ(V:する)れている→実現されている
発注(S:サ/C:抽象物/D:ビジネス)した(V:する)→発注した
成功(S:サ/C:抽象物)し(V:する)なかった→成功しなかった
すなわち、サ変の名詞があって、それにするという動詞の活用形がきて、語尾がある(活用形が原型などの場合は、語尾はない)Vの右側は、動詞の原形である。jumanppが提供する。
サ変名詞で終わりたい時は、文章的には簡単である。prolog二分木では、サ変名詞を確実に把握できるので、サ変名詞のあるところでは、自由に、自然に、文章を終われる。
次に多いのは、動詞1という終わり方である。これは、動詞を最も単純に使って文章を終わりにさせる方法である。例としては、
示して(V:示す)いる
下して(V:下す)いる
こなして(V:こなす)いる
用い(V:用いる)られる
考え(V:考える)られない
言わ(V:言う)れる
語ら(V:語る)れた
描く(V:描く)
いう(V:いう)
ある(V:ある)
など。
jumanppは、動詞の原形を必ずくれるので、動詞が来れば、多様な形で文章を終わらせることができる。
ただ、原型から、活用形を導き出す場合、原型の最後の1文字を変更するのが基本的な方法だが、「行う」が「行って」と「って」になるパターンがある。このルールが、私には複雑でよくわかっていない。データベースに動詞のパターンを登録しておくのが、一番簡単なように思える。
次の「動詞2」というのは、終わりのフレーズに動詞が二つある場合だ。たとえば、
溶け(V:溶ける)込んで(V:込む)いる
描き (描く) 出さ (出す) れている
成り (成る) 込む (込む)
受け入れ (受け入れる) なければなら (なる) なくなっている
などのパターンである。
次に多い、普通名詞3は、
劇場 (普) 上映 (サ) さ (する) れた
全面 (普) 開放 (サ) さ (する) れた
毎正時 (普) 送出 (サ) さ (する) れる
社名 (普) 変更 (サ) して (する) いる
行政 (普) 移管 (サ) して (する) いる
など、普通名詞とサ変名詞が連結しているパターンである。
最も単純な、終句で終わるパターンは、7位と意外に少ない。これは、ほとんどの場合、ノードの値が終わりになっている場合だと思う。全部を調べてみた。
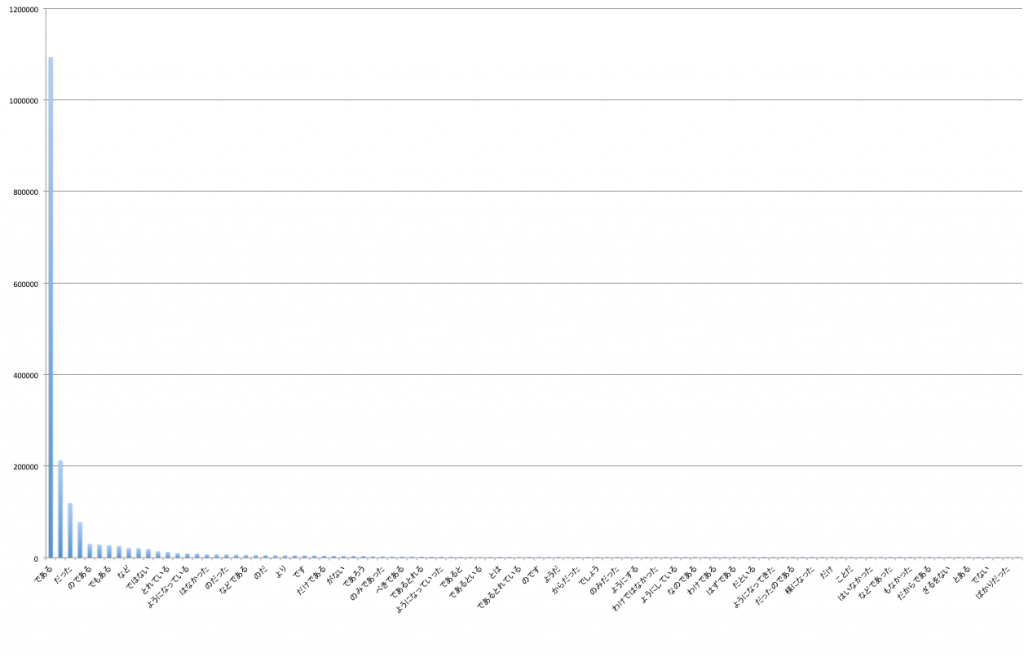
縦軸は、文末に現れる頻度である。ちょっとみにくいが、圧倒的に「である」が多い。あとはカスみたいなものである。Wikipediaは「である」調なので、デスマス調の場合は「です」ということになる。「である」は、その前の言葉にあまり依存しないとても便利な終わりの句である。否定の時は、「ではない」、受け身の時は、「られる」とかにすればよい。
5月ごろに、それまでのwikipedia prologのフォーマット上の問題が見つかって、その訂正を一旦保留していたが、先週から数日かけて、全て作り直した。
prolog宣言文の数は、17,843,495個あり544個のファイルに分割されている。データサイズは合計11.3Gバイトだ。
前にも書いたが、たとえば、いくつかのキーワードを持った宣言文をprologで拾い出そうとすると、一つのファイルの1秒かかる。使えない。そこで、一つ一つの宣言文が含むキーワード(名詞や動詞句など、二分木の葉になっているもの)を宣言文のIDとともにデータベース(mariadb)に登録した。そうすると、intersectコマンドを使って、キーワードを同時に持つ宣言文を拾い出せる。
マルチスレッドを利用することを前提に、mariadbのテーブルを25個に分けた。25個のスレッド(java)で、たとえば人間とロボットというキーワードを持つ宣言文を検索させると1秒以下で、すべてのwikipedia本文から、700余の文章(宣言文のID)を拾い出す。凄まじい速さだ。データベースの凄さだ。(indexを張っておかないといけない)
同時に持った宣言文のIDを拾いだしたら、その宣言文自体が欲しい。そこで、宣言文IDと宣言文そのものを、これまた25個のテーブルにデータベース化した。
そこで、人間とロボットというキーワードを持つ宣言文IDを検索し、それを元に宣言文そのものを取り出すためにかかった時間は、1.7秒だ。宣言文IDをつかって、ベタのファイルからその宣言文を取り出そうとすると、これほど高速にはならない。1.7秒は使える範囲だ。
だいぶ環境は整ってきた。
core-i9 ubuntu18.04マシンに、ファイアウォールを設定しようと思って、iptableを探したが見当たらない。ubuntuは、ufwというシステムを使うらしい。頭が古くなっているのを実感する。
sudo ufw allow 80/tcp
こんな感じで設定する。拒否するときは、
sudo ufw deny 3306
と言う感じ。IPアドレスをしていするときは、
sudo ufw allow from 192.168.0.1 to any port 3306
と言う感じ。有効にするときは、
sudo ufw enable
sshでリモートから接続しているときに、sshポートを開けないままやると、以後繋げなくなってしまうので注意しなさいと言うメッセージが出る。いかにもありそうな失敗だ。
無効にするときは、
sudo ufw disable
状態を確認したいときは、
sudo ufw status
長めに出力したいときは、
sudo ufw status verbose
となる。リロードするときは、
sudo ufw reload
ルールを削除したいときは、一旦ルールを番号で出す。
sudo ufw status numbered
番号を指定して削除する。たとえば、
sudo ufw delete 3
とか。
iptableよりも、はるかに使いやすいのは確かだ。
Core-i9 (ubuntu18.04)でやる作業が多くなったので、macから、VNCでつなぐことにした。
いろいろ調べて、vncのセットアップファイル、.vnc/xstartupを次のようにした。
#!/bin/sh # Uncomment the following two lines for normal desktop: # unset SESSION_MANAGER # exec /etc/X11/xinit/xinitrc #日本語入力メソッド iBus export GTK_IM_MODULE=ibus export XMODIFIERS="@im=ibus" export QT_IM_MODULE=ibus ibus-daemon -d -x [ -x /etc/vnc/xstartup ] && exec /etc/vnc/xstartup [ -r $HOME/.Xresources ] && xrdb $HOME/.Xresources xsetroot -solid grey vncconfig -iconic & #x-terminal-emulator -geometry 80x24+10+10 -ls -title "$VNCDESKTOP Desktop" & #x-window-manager & export XKL_XMODMAP_DISABLE=1 /etc/X11/Xsession /usr/bin/startlxde
ウィンドウマネージャーは、Lxdeという軽量のものにして、それだけでは、日本語入力がうまく行かないので、中程にある設定を入れている。どこかのサイトから頂いている。
prologのfact文にしたwikipediaファイルを検索するためのjavaプログラムを作成した。prologによる開発効率が悪いので、あっさりjavaで、という狙いだった。プログラム自体は簡単にできた。ただ、じっさいそれで、「ロボット」と「模型」といった、2語を同時に含む文章を検索させると、1ファイルあたり7.8秒かかる。wikipedia本文の全部を544ファイルにしてあるうちの1ファイルにこれくらいの時間がかかるということだ。
prologにしてあるからで、元々のテキストから検索すれば、もっと早いのではないかと思われるかもしれない。単純な検索ならば、もっと早くなる可能性がないとは言えないが、prologのfact化してあるものは、そこにjuman++によるカテゴリ、品詞データ、ドメインなどの形態素解析やknpによる構文解析結果がはめ込まれているので、それらを含めれば比べ物にならない。つまり、元々のテキストに、こうした自然言語解析をやりながら、データの検索をかければ、もっと時間がかかってしまうだろうということだ。
もちろん、googleなどは、もっと上手いことをやっているんだろうが、それほどの環境やシステム、能力を持っていない。
となると、prolog化したwikipediaは、キホ的なところは、prologで検索しなければならないと思われる。
swiprologは、プログラム/データをバイナリ化して保持するので、自分の思う通りの検索をやらせれば、もっともっと速かった。
prologというもののすごさがわかる。
新しくMacBook (MacOS 10.14.6)にjuman++とknpをいれた。MacProでは、普通に使っていたので、問題なくインストールできるかと思った。ただ、昔のことでよく覚えていない。
juman++は、
./configure --prefix=/usr/local/jumanpp make sudo make install
で入れて、knpは、
./configure --prefix=/usr/local/knp --with-juman-prefix=/usr/local/jumanpp make sudo make install
でいれた。
echo 今日はいい天気ですね | /usr/local/jumanpp/bin/jumanpp | /usr/local/knp/bin/knp
をやると、
(null): can't open JUMAN.grammar . exit(2)
となる。およ!どうなってるの。いろいろやったが、結局、jumanを別にインストールして、knpのコンパイル時に、
./configure --prefix=/usr/local/knp --with-juman-prefix=/usr/local/juman
とjumanppではなくjumanのインストール先を指定したら、
echo 今日はいい天気ですね | /usr/local/jumanpp/bin/jumanpp | /usr/local/knp/bin/knp # S-ID:1 KNP:4.19-CF1.1 DATE:2019/08/21 SCORE:-19.04210 今日は─────┐ <体言><NE:DATE:今日> いい─────┤ <用言:形><格解析結果:ガ/天気;カラ/-;時間/-;ガ2/-> 天気ですね<体言><用言:判><格解析結果:ガ/-;時間/今日> EOS
とちゃんとjuman++ で結果を出した。ただ、これでよかったのかどうかはわからない。juman++だけでいいのかもしれない。とうめんこれでやる。
またおんなじことを繰り返さないようにメモしておく。